
2020-05-11

Practice Final Questions .
Yusuf Amer, Rabia Mohiuddin, Hieu Tran
(Edited: 2020-05-11) 3. Give sufficient rules for a database to be able to perform recovery when: (a) undo logging is being used (b) redo logging is being used, (c) undo-redo logging is being used. (U1) If T modifies X, then a log of the form ⟨T,X,v⟩ must be written before the new value of X is written to disk. (U2) If a transaction commits, then its COMMIT log record must be written to disk only after all database elements changed by the transaction have been written to disk, but as soon thereafter as possible. [March 25th - Slide 15] (R1) [Also called the write-ahead logging (WAL) rule] Before modifying X on disk, all log records pertaining to this modification of X (that is, both the update record ⟨T,X,v⟩ and the ⟨COMMIT T⟩ record) must appear on disk. [March 25th - Slide 15] (UR1) Before modifying X on disk because of T, it is necessary that the update record ⟨T,X,v,w⟩ appear on disk. (v is the old value; w is the new) (UR2) A ⟨COMMIT T⟩ must be flushed to disk as soon as it appears in the log. [April 6th - Slide 12]
4. Explain how a nonquiescent checkpoint is done if we are using undo-redo logging. Explain how an non-quiescent archive is performed if we are using undo-redo logging. Checkpoint [April 6th - Slide 6] 1) Write a ⟨START CKPT(T1,...,Tk)⟩ to the log 2) Write all dirty buffers to disk. 3) Write an ⟨END CKPT⟩, flush the log. If this kind of checkpoint is being used and a crash occurs, then we look backwards through the log for the first <Start Ckpt (T1 .. Tk)> or <End ckpt>. If we see an <End ckpt>, we know we only have to consider transactions that started after the <Start Ckpt (T1 .. Tk)> If we see a <Start Ckpt (T1 .. Tk)> but no <End ckpt>, then we need to only consider after the transactions T1...Tk began. Archive [April 8th - Slide 4] 1) Write a ⟨START DUMP⟩ record. 2) Perform a check point. 3) Perform a full or incremental dump of the data disks as desired, copying the data in some fixed order, so don't copy the same info twice and eventually finish copying. 4) Copy enough of the log that it includes at least the prefix of the log up to an including the end of item (2). 5) Write a log record ⟨END DUMP⟩. We can now throw away old log from last archive to previous checkpoint.
Yusuf Amer, Rabia Mohiuddin, Hieu Tran
<pre>
3. Give sufficient rules for a database to be able to perform recovery when: (a) undo logging is being used (b) redo logging is being used, (c) undo-redo logging is being used.
(U1) If T modifies X, then a log of the form ⟨T,X,v⟩ must be written before the new value of X is written to disk.
(U2) If a transaction commits, then its COMMIT log record must be written to disk only after all database elements changed by the transaction have been written to disk, but as soon thereafter as possible. [March 25th - Slide 15]
(R1) [Also called the write-ahead logging (WAL) rule] Before modifying X on disk, all log records pertaining to this modification of X (that is, both the update record ⟨T,X,v⟩ and the ⟨COMMIT T⟩ record) must appear on disk. [March 25th - Slide 15]
(UR1) Before modifying X on disk because of T, it is necessary that the update record ⟨T,X,v,w⟩ appear on disk. (v is the old value; w is the new)
(UR2) A ⟨COMMIT T⟩ must be flushed to disk as soon as it appears in the log. [April 6th - Slide 12]
----
4. Explain how a nonquiescent checkpoint is done if we are using undo-redo logging. Explain how an non-quiescent archive is performed if we are using undo-redo logging.
Checkpoint [April 6th - Slide 6]
1) Write a ⟨START CKPT(T1,...,Tk)⟩ to the log
2) Write all dirty buffers to disk.
3) Write an ⟨END CKPT⟩, flush the log.
If this kind of checkpoint is being used and a crash occurs, then we look backwards through the log for the first <Start Ckpt (T1 .. Tk)> or <End ckpt>.
If we see an <End ckpt>, we know we only have to consider transactions that started after the <Start Ckpt (T1 .. Tk)>
If we see a <Start Ckpt (T1 .. Tk)> but no <End ckpt>, then we need to only consider after the transactions T1...Tk began.
Archive [April 8th - Slide 4]
1) Write a ⟨START DUMP⟩ record.
2) Perform a check point.
3) Perform a full or incremental dump of the data disks as desired, copying the data in some fixed order, so don't copy the same info twice and eventually finish copying.
4) Copy enough of the log that it includes at least the prefix of the log up to an including the end of item (2).
5) Write a log record ⟨END DUMP⟩. We can now throw away old log from last archive to previous checkpoint.
</pre>
5. Briefly explain and give an example: (a) two-phase locking, (b) strict two phase locking, (c) recoverable schedule, (d) avoids cascading rollbacks schedule
.
a)For every transaction, all lock requests must precede all unlock requests.
t1(gets lock 1), t1(gets lock 2), t1(unlocks lock 1), t1(unlocks lock 2)
.
b)strict 2pl is the same as 2pl except it can't release any locks until it is ready to release all of them
t1(gets lock 1), t1(gets lock 2), t1(gets exclusive lock 3), t1 does work, t1(unlocks lock 1), t1(unlocks lock 2), t1(unlocks lock 3)
.
c)A schedule is recoverable if each transaction commits only after each transaction from which it has read commits.
W1(A), W1(B), W2(A), R2(B), C1, C2
.
d)A schedule avoids cascading rollbacks (ACR) if transactions may read only values written by committed transactions
W1(A), W1(B), W2(A), C1, R2(B), C2
.
(group: Andrew, Vlad, Gavin)
(Edited: 2020-05-11) 5. Briefly explain and give an example: (a) two-phase locking, (b) strict two phase locking, (c) recoverable schedule, (d) avoids cascading rollbacks schedule
.
a)For every transaction, all lock requests must precede all unlock requests.
t1(gets lock 1), t1(gets lock 2), t1(unlocks lock 1), t1(unlocks lock 2)
.
b)strict 2pl is the same as 2pl except it can't release any locks until it is ready to release all of them
t1(gets lock 1), t1(gets lock 2), t1(gets exclusive lock 3), t1 does work, t1(unlocks lock 1), t1(unlocks lock 2), t1(unlocks lock 3)
.
c)A schedule is recoverable if each transaction commits only after each transaction from which it has read commits.
W1(A), W1(B), W2(A), R2(B), C1, C2
.
d)A schedule avoids cascading rollbacks (ACR) if transactions may read only values written by committed transactions
W1(A), W1(B), W2(A), C1, R2(B), C2
.
(group: Andrew, Vlad, Gavin)
Group: Haitao Huang, Yulong Ran, Tuong Nguyen
1. Suppose T(R)=30000 and T(S)=20000 and S and R share only one attribute Y where V(R,Y)=100, V(S,Y) =1000.. What would be our cost-based plan selection estimate for the number of tuples returned by W=σA<c(R)? R⋈S ? W=σA<c(R): T(W) = T(R) / 3 = 30000/3 = 10000. R⋈S: T(R⋈S) =T(R)⋅T(S)/max(V(R,Y),V(S,Y)) = 30000 * 20000 / 1000 = 600000
2. Briefly explain how the SQL ANALYZE command works for sqlite as well as what kind of statistics are stored in the table sqlite_stat1. The ANALYZE command in SQLITE gathers statistics about tables and indices and stores the collected information in internal tables of the database where the query optimizer can access the information and use it to help make better query planning choices. If no arguments are given, all attached databases are analyzed. If a schema name is given as the argument, then all tables and indices in that one database are analyzed. By default, the statistical information in sqlite will be stored in the table sqlite_stat1 and will be used by the query optimizer to determine the query plan.sqlite_stat1 will have the following schema: sqlite_stat1(tbl,idx,stat); There is normally one row per index, with the index identified by the name in the sqlite_stat1.idx column. The sqlite_stat1.tbl column is the name of the table to which the index belongs. In each such row, the sqlite_stat.stat column will be a string consisting of a list of integers followed by zero or more arguments. The first integer in this list is the approximate number of rows in the index. (The number of rows in the index is the same as the number of rows in the table, except for partial indexes.) The second integer is the approximate number of rows in the index that have the same value in the first column of the index. The third integer is the number number of rows in the index that have the same value for the first two columns. The N-th integer (for N>1) is the estimated average number of rows in the index which have the same value for the first N-1 columns. For a K-column index, there will be K+1 integers in the stat column. If the index is unique, then the last integer will be 1.(Edited: 2020-05-11)
Group: Haitao Huang, Yulong Ran, Tuong Nguyen
1. Suppose T(R)=30000 and T(S)=20000 and S and R share only one attribute Y where V(R,Y)=100, V(S,Y) =1000.. What would be our cost-based plan selection estimate for the number of tuples returned by W=σA<c(R)? R⋈S ?
W=σA<c(R): T(W) = T(R) / 3 = 30000/3 = 10000.
R⋈S: T(R⋈S) =T(R)⋅T(S)/max(V(R,Y),V(S,Y)) = 30000 * 20000 / 1000 = 600000
----
2. Briefly explain how the SQL ANALYZE command works for sqlite as well as what kind of statistics are stored in the table sqlite_stat1.
The ANALYZE command in SQLITE gathers statistics about tables and indices and stores the collected information in internal tables of the database where the query optimizer can access the information and use it to help make better query planning choices. If no arguments are given, all attached databases are analyzed. If a schema name is given as the argument, then all tables and indices in that one database are analyzed.
By default, the statistical information in sqlite will be stored in the table sqlite_stat1 and will be used by the query optimizer to determine the query plan.
sqlite_stat1 will have the following schema: sqlite_stat1(tbl,idx,stat);
There is normally one row per index, with the index identified by the name in the sqlite_stat1.idx column. The sqlite_stat1.tbl column is the name of the table to which the index belongs. In each such row, the sqlite_stat.stat column will be a string consisting of a list of integers followed by zero or more arguments. The first integer in this list is the approximate number of rows in the index. (The number of rows in the index is the same as the number of rows in the table, except for partial indexes.) The second integer is the approximate number of rows in the index that have the same value in the first column of the index. The third integer is the number number of rows in the index that have the same value for the first two columns. The N-th integer (for N>1) is the estimated average number of rows in the index which have the same value for the first N-1 columns. For a K-column index, there will be K+1 integers in the stat column. If the index is unique, then the last integer will be 1.
Team Members: Brett Dispoto, Kevin Ho
Give an example different from class of a schema a mediator might expose to application queries and how queries to that schema might be re-written to two distinct data sources.
Suppose we want to implement a data warehouse of Government Employees. There are several governmental agencies such as federal and state which keep their own employee databases.
----------------------------------------------------------------- Part 1 solution: A mediator might expose the schema: GovEmpMediator(socialSecurity, agency, salary, fname, lname) ----------------------------------------------------------------- ----------------------------------------------------------------- Part 2 solution: Now suppose we receive the query for employees with million dollar salaries: SELECT fname, lname FROM GovEmpMediator WHERE salary>1000000; For a Federal employee database, we would rewrite this as: SELECT first_name, last_name FROM FedEmps WHERE payGrade>5 For a State employee database, we would rewrite this as: SELECT first, last FROM CaliforniaEmployees WHERE salary>1000000; -----------------------------------------------------------------(Edited: 2020-05-11)
Team Members: '''''<u>Brett Dispoto, Kevin Ho</u>'''''
<u>'''''Give an example different from class of a schema a mediator might expose to application queries and how queries to that schema might be re-written to two distinct data sources.'''''</u>
Suppose we want to implement a data warehouse of Government Employees. There are several governmental agencies such as federal and state which keep their own employee databases.
<pre>
-----------------------------------------------------------------
Part 1 solution:
A mediator might expose the schema:
GovEmpMediator(socialSecurity, agency, salary, fname, lname)
-----------------------------------------------------------------
-----------------------------------------------------------------
Part 2 solution:
Now suppose we receive the query for employees with million dollar salaries:
SELECT fname, lname
FROM GovEmpMediator
WHERE salary>1000000;
For a Federal employee database, we would rewrite this as:
SELECT first_name, last_name
FROM FedEmps
WHERE payGrade>5
For a State employee database, we would rewrite this as:
SELECT first, last
FROM CaliforniaEmployees
WHERE salary>1000000;
-----------------------------------------------------------------
</pre>
Group members: Edgar Miranda and Spencer Edwards
Problem #10
Define the following OLAP concepts (a) star-schema, (b) slicing data, (d) cube. How would the roll up operation in SQL help in computing frequent item sets?
Define the following OLAP concepts (a) star-schema, (b) slicing data, (d) cube. How would the roll up operation in SQL help in computing frequent item sets?
(a) Star-schema
A star schema consists of the schema for the fact table, together with several other relation called dimension tables which are linked to via foreign key relationships.
For example, if we use the example of Sales (serialNo, date, dealer, price), this would be considered our fact table. SerialNo, date, and dealer, are our dimension attributes. Price would be our dependent attribute. Autos, Date, and Dealer would be our dimensions tables.
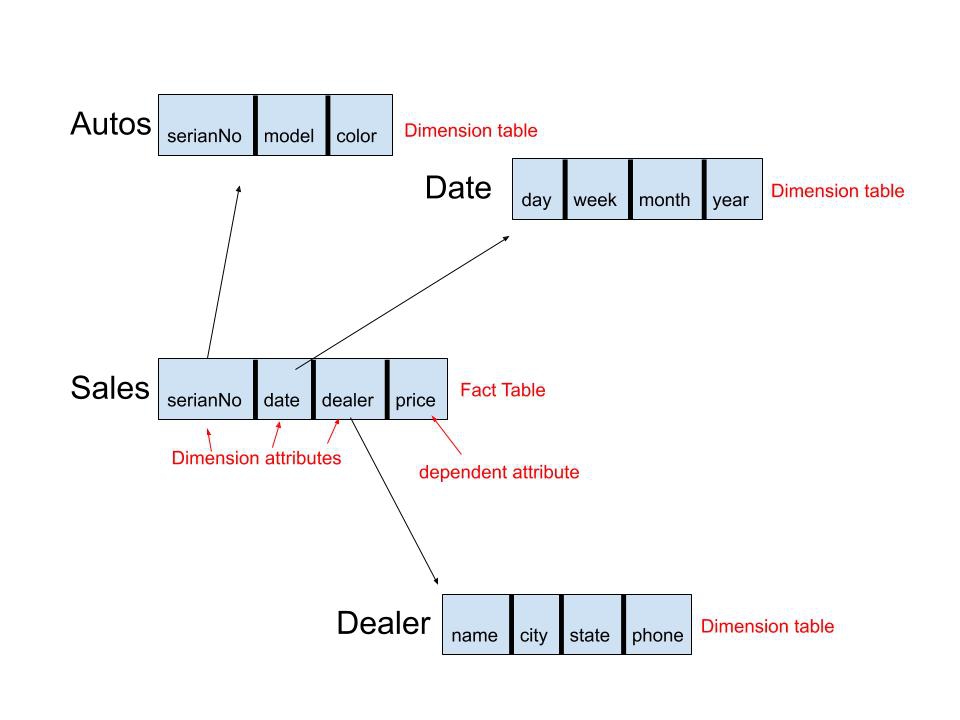
(b) Slicing data
Slicing is in simple terms is taking a dataset and filtering it based on an attribute -- taking a slice so to speak. This is done using a where clause. To visualize, if you had data that had three dimensions to it, Date, Car Dealer, and Car, Slicing would be the case where you hold some quality, say car color constant (via a where clause). The returned result is the slice of the three dimensional cube (as a slice has two dimensions). In this case you have all of the times and all of the car dealers with that particular color car.
Slicing is in simple terms is taking a dataset and filtering it based on an attribute -- taking a slice so to speak. This is done using a where clause. To visualize, if you had data that had three dimensions to it, Date, Car Dealer, and Car, Slicing would be the case where you hold some quality, say car color constant (via a where clause). The returned result is the slice of the three dimensional cube (as a slice has two dimensions). In this case you have all of the times and all of the car dealers with that particular color car.
(c)Cube
An Olap cube is a technology that stores data in an optimized way to provide a quick response to various types of complex queries by using dimensions and measures. Most cubes store pre-aggregates of the measures with its special storage structure to provide quick response to queries. Olap cubes store analytical data rather than transactional. Traditional sql tables are generally considered to be two dimensional whereas Olap cubes allow for a vast variety of comparisons and analysis that would be more difficult in a more traditional database structure.
(d)How would the roll up operation in SQL help in computing frequent item sets
ROLLUP enables a SELECT statement to calculate multiple levels of subtotals across a specified group of dimensions. It also calculates a grand total. ROLLUP is a simple extension to the GROUP BY clause. The ROLLUP extension is highly efficient, adding minimal overhead to a query.
(Edited: 2020-05-11) ROLLUP enables a SELECT statement to calculate multiple levels of subtotals across a specified group of dimensions. It also calculates a grand total. ROLLUP is a simple extension to the GROUP BY clause. The ROLLUP extension is highly efficient, adding minimal overhead to a query.
Group members: Edgar Miranda and Spencer Edwards
<br><br>
Problem #10
<br>
Define the following OLAP concepts (a) star-schema, (b) slicing data, (d) cube. How would the roll up operation in SQL help in computing frequent item sets?
<br><br>
(a) Star-schema
A star schema consists of the schema for the fact table, together with several other relation called dimension tables which are linked to via foreign key relationships.
<br>
<br>
For example, if we use the example of Sales (serialNo, date, dealer, price), this would be considered our fact table. SerialNo, date, and dealer, are our dimension attributes. Price would be our dependent attribute. Autos, Date, and Dealer would be our dimensions tables.
((resource:Untitled drawing (1).jpg|Resource Description for Untitled drawing (1).jpg))
(b) Slicing data
<br><br>
Slicing is in simple terms is taking a dataset and filtering it based on an attribute -- taking a slice so to speak.
This is done using a where clause.
To visualize, if you had data that had three dimensions to it,
Date, Car Dealer, and Car,
Slicing would be the case where you hold some quality, say car color constant (via a where clause). The returned result is the slice of the three dimensional cube (as a slice has two dimensions). In this case you have all of the times and all of the car dealers with that particular color car.
<br><br>
(c)Cube
<br><br>
An Olap cube is a technology that stores data in an optimized way to provide a quick response to various types of complex queries by using dimensions and measures. Most cubes store pre-aggregates of the measures with its special storage structure to provide quick response to queries. Olap cubes store analytical data rather than transactional.
Traditional sql tables are generally considered to be two dimensional whereas Olap cubes allow for a vast variety of comparisons and analysis that would be more difficult in a more traditional database structure.
<br><br>
(d)How would the roll up operation in SQL help in computing frequent item sets
<br><br>
ROLLUP enables a SELECT statement to calculate multiple levels of subtotals across a specified group of dimensions. It also calculates a grand total. ROLLUP is a simple extension to the GROUP BY clause. The ROLLUP extension is highly efficient, adding minimal overhead to a query.
Group #5: Devin Gonzales, Akshay Sud, Minh Ngo
Problem #7
Give the parallel algorithm from class for computing the join of two relations R⋈S.
- First, we create a hash function h dependent on the common attributes shared between R and S
- Compute the hash h(t) for each tuple in R and S
- For each i = h(t), Mi receives all tuples t corresponding with hash i
- After receiving all tuples, M computes R⋈S on its received tuples and outputs the result
Give its cost on N machines.
- Determining the hash function doesn’t require any IO ops
- Hashing each tuple in R and S takes B(R) + B(S) total IO ops, on N machines the total cost for this part of the join is (B(R) + B(S)) / N
- The next step requires distribution over ((N - 1) / N)(B(R) + B(S)) blocks, which ideally would be negligible as N machines goes to a greater number, then doing (B(R) + B(S)) / N ops on N machines, which ends up being B(R) + B(S) total ops
- The next step is 3(B(R) + B(S)) / N IO ops to join the final result
- At the end of the join, the total cost of the IO operations is 5(B(R) + B(S)) / N operations, which for N >= 2 machines is actually a better performance than the standard 3(B(R) + B(S)) operations that a traditional join algorithm would cost.
Give the distributed algorithm from class for computing R⋈S on two machines.
(Edited: 2020-05-11) - Determine between R and S, which one has the smaller table.
- Send a copy of the smaller table to the other site, then compute the join there.
Assume R is the smaller table:
- The machine with S will compute πY(S) and send it to the machine with R.
- The machine with R will compute R ⋉ S and send it to machine with S.
- The machine with S uses R ⋉ S to compute R(X,Y) ⋈ S(Y,Z).
Similarly, if S is the smaller table, we repeat this algorithm with appropriately swapped table values.
Group #5: Devin Gonzales, Akshay Sud, Minh Ngo
'''<u>Problem #7</u>'''
'''Give the parallel algorithm from class for computing the join of two relations R⋈S.'''
# First, we create a hash function h dependent on the common attributes shared between R and S
# Compute the hash h(t) for each tuple in R and S
# For each i = h(t), Mi receives all tuples t corresponding with hash i
# After receiving all tuples, M computes R⋈S on its received tuples and outputs the result
'''Give its cost on N machines. '''
* Determining the hash function doesn’t require any IO ops
* Hashing each tuple in R and S takes B(R) + B(S) total IO ops, on N machines the total cost for this part of the join is (B(R) + B(S)) / N
* The next step requires distribution over ((N - 1) / N)(B(R) + B(S)) blocks, which ideally would be negligible as N machines goes to a greater number, then doing (B(R) + B(S)) / N ops on N machines, which ends up being B(R) + B(S) total ops
* The next step is 3(B(R) + B(S)) / N IO ops to join the final result
* At the end of the join, the total cost of the IO operations is '''5(B(R) + B(S)) / N''' operations, which for N >= 2 machines is actually a better performance than the standard 3(B(R) + B(S)) operations that a traditional join algorithm would cost.
'''Give the distributed algorithm from class for computing R⋈S on two machines.'''
# Determine between R and S, which one has the smaller table.
# Send a copy of the smaller table to the other site, then compute the join there.
Assume R is the smaller table:
# The machine with S will compute πY(S) and send it to the machine with R.
# The machine with R will compute R ⋉ S and send it to machine with S.
# The machine with S uses R ⋉ S to compute R(X,Y) ⋈ S(Y,Z).
Similarly, if S is the smaller table, we repeat this algorithm with appropriately swapped table values.
Claire Lin
Iris Cheung
Neeval Kumar
8. Define the following distributed locking concepts: (a) centralized locking, (b) Lock Coordinator, (c) primary copy locking. Suggest an algorithm to avoid deadlocks in the distributed setting.
(a)Centralized locking uses a single lock site to maintain a lock table for the elements. A transaction will send a request to the lock site for a lock on element X. Then, the lock site will grant or deny the lock as appropriate. The single lock site could become a bottleneck if there are many sites and transactions happening at the same time because if the lock site crashes other transactions cannot acquire the lock.
(b) A lock coordinator is a component of a distributed transaction that is responsible for gathering all the locks needed for the transaction at different sites where the transaction occurred. The lock coordinator can lock resources that are also on its own side, but needs to communicate through messages to lock resources on other sites.
(c) In primary copy locking, an element X, that is distributed among many sites in a database, has a “primary copy” located at site P. When acquiring a lock for this element X, the transaction will send a request to the lock table of site P, which will either accept or deny the request.
The best way to avoid deadlocks is to use timeouts, which is if the time is exceeded (by an appropriate time), then a deadlock is assumed and the transaction is rolled back.
if(time exceeds a certain amount of time){
Then assume deadlock detected. Transaction rolled back. }
(Edited: 2020-05-11) Claire Lin
Iris Cheung
Neeval Kumar
----
''8. Define the following distributed locking concepts: (a) centralized locking, (b) Lock Coordinator, (c) primary copy locking. Suggest an algorithm to avoid deadlocks in the distributed setting.''
----
(a)Centralized locking uses a single lock site to maintain a lock table for the elements. A transaction will send a request to the lock site for a lock on element X. Then, the lock site will grant or deny the lock as appropriate. The single lock site could become a bottleneck if there are many sites and transactions happening at the same time because if the lock site crashes other transactions cannot acquire the lock.
----
(b) A lock coordinator is a component of a distributed transaction that is responsible for gathering all the locks needed for the transaction at different sites where the transaction occurred. The lock coordinator can lock resources that are also on its own side, but needs to communicate through messages to lock resources on other sites.
----
(c) In primary copy locking, an element X, that is distributed among many sites in a database, has a “primary copy” located at site P. When acquiring a lock for this element X, the transaction will send a request to the lock table of site P, which will either accept or deny the request.
----
The best way to avoid deadlocks is to use timeouts, which is if the time is exceeded (by an appropriate time), then a deadlock is assumed and the transaction is rolled back.
if(time exceeds a certain amount of time){
Then assume deadlock detected. Transaction rolled back. }
Problem 6: Zizhen Huang, Lalitha Donga, Nick Dowell
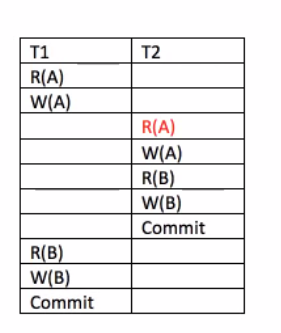 Exclusive Locks will solve this problem!
Exclusive Locks will solve this problem!

(Edited: 2020-05-11)
Exclusive Locks will solve this problem!
Problem 6: Zizhen Huang, Lalitha Donga, Nick Dowell
((resource:Talbe - Problem 6 Practice Final.PNG|Resource Description for Talbe - Problem 6 Practice Final.PNG))
Exclusive Locks will solve this problem!
((resource:Table 2 Problem 6 practice final.PNG|Resource Description for Table 2 Problem 6 practice final.PNG))
(c) 2026 Yioop - PHP Search Engine