
2020-12-01

Practice Final Thread .
Please post your group's problem solutions to this thread. Make sure to list all group members on your solution.
Best,
Chris
Please post your group's problem solutions to this thread. Make sure to list all group members on your solution.
Best,
Chris
2020-12-07
Question - 10 (Picked from the lecture notes)
- Total Data Quality Management - this is a four cycle process to improve data quality by definition (of quality dimensions), measurement (of percentages of data of given quality across each dimension), analysis (of causes of lack of data quality), and improvement (specific actions such as random input audits to be taken to fix lack of data quality)
- 5 V's of Big Data
- Volume: the amount of data, also referred to the data "at rest".
- Velocity: the speed at which data come in and go out, data "in motion".
- Variety: the range of data types and sources that are used, data in its "many forms".
- Veracity: the amount of data "in doubt" due to data inconsistency and incompleteness, to ambiguities present in the data, as well as latency or certain data points that might be derived from estimates or approximations.
- Value: the economic value of the data as quantified using the total cost of ownership (TCO) and return on investment (ROI).
- Resilient Distributed Dataset: It is a data structure which is essentially read-only, partitioned collection of records. RDDs can only be created through deterministic operations on either (1) data in stable storage or (2) other RDDs. We can manipulate RDDs via sequences of operations such as: map, filter, and join. Outputs in such a sequence of operations need not be materialized, but the lineage of any RDD is tracked and allows it to be materialized if needed.
Question - 10 (Picked from the lecture notes)
* Total Data Quality Management - this is a four cycle process to improve data quality by definition (of quality dimensions), measurement (of percentages of data of given quality across each dimension), analysis (of causes of lack of data quality), and improvement (specific actions such as random input audits to be taken to fix lack of data quality)
* 5 V's of Big Data
- Volume: the amount of data, also referred to the data "at rest".
- Velocity: the speed at which data come in and go out, data "in motion".
- Variety: the range of data types and sources that are used, data in its "many forms".
- Veracity: the amount of data "in doubt" due to data inconsistency and incompleteness, to ambiguities present in the data, as well as latency or certain data points that might be derived from estimates or approximations.
- Value: the economic value of the data as quantified using the total cost of ownership (TCO) and return on investment (ROI).
* Resilient Distributed Dataset: It is a data structure which is essentially read-only, partitioned collection of records. RDDs can only be created through deterministic operations on either (1) data in stable storage or (2) other RDDs. We can manipulate RDDs via sequences of operations such as: map, filter, and join. Outputs in such a sequence of operations need not be materialized, but the lineage of any RDD is tracked and allows it to be materialized if needed.
Question - 9
5 Sample URLs (which will be seed sites) and their links to each are mentioned below:
5 Sample URLs (which will be seed sites) and their links to each are mentioned below:
- abc.com -> def.com; mno.com;
- def.com -> ghi.com;
- ghi.com -> no links
- jkl.com -> abc.com; def.com; ghi.com;
- mno.com -> no links
OPIC algorithm gives initial equal value to all the seed sites, let us suppose that each site is given 6`. So, all the seed site pages will be downloaded first and their money value will get distributed equally among the links that are found on that page. If no links found, money value will just remain with that page as it is.
- abc.com is fetched -> money distributed to def.com and mno.com - 3` each;[new money values - 0, 9, 6, 6, 9; any of the sites with 9 weight will be crawled, let's take def.com]
- def.com is fetched -> full money given to ghi.com - 9`; [new money values - 0, 0, 15, 6, 9; site with weight 15 will be crawled]
- ghi.com is fetched -> money given to none; [new money values - 0, 0, 15, 6, 9; site with 9 weight will be crawled]
- mno.com is fetched -> money given to none; [new money values - 0, 0, 15, 6, 9; site with 6 weight will be crawled]
- jkl.com is fetched -> money given to abc.com, def.com , ghi.com - 2` each; [new money values - 2, 2, 17, 0, 9]
We have successfully crawled all the seed sites once!(Edited: 2020-12-07)
Question - 9
----
5 Sample URLs (which will be seed sites) and their links to each are mentioned below:
* abc.com -> def.com; mno.com;
* def.com -> ghi.com;
* ghi.com -> no links
* jkl.com -> abc.com; def.com; ghi.com;
* mno.com -> no links
----
OPIC algorithm gives initial equal value to all the seed sites, let us suppose that each site is given 6$. So, all the seed site pages will be downloaded first and their money value will get distributed equally among the links that are found on that page. If no links found, money value will just remain with that page as it is.
----
* abc.com is fetched -> money distributed to def.com and mno.com - 3$ each;[new money values - 0, 9, 6, 6, 9; any of the sites with 9 weight will be crawled, let's take def.com]
* def.com is fetched -> full money given to ghi.com - 9$; [new money values - 0, 0, 15, 6, 9; site with weight 15 will be crawled]
* ghi.com is fetched -> money given to none; [new money values - 0, 0, 15, 6, 9; site with 9 weight will be crawled]
* mno.com is fetched -> money given to none; [new money values - 0, 0, 15, 6, 9; site with 6 weight will be crawled]
* jkl.com is fetched -> money given to abc.com, def.com , ghi.com - 2$ each; [new money values - 2, 2, 17, 0, 9]
----
We have successfully crawled all the seed sites once!
Group 1: David Bui, Mariia Surmenok
<u>Question 1</u>
a) relative location - for each record store each attribute value in the order defined by its schema without specifying the name of the attribute. If the size can be variable, need to either specify the size before the item or use a delimiter.
Example for schema (name, student id, address): |Mariia Surmenok|13711111|Redwood City,CA
b) embedded identification: store the attribute type and name before the attribute value [VARCHAR][NAME][DAVID][INT][PHONENUMBER][999999]|
c) store multivalued attributes such that the first is stored in a record but for the rest, the pointer is used pointing to another location with the remaining values For example, pets names can be multivalued attributes if there are multiple pets. Here's the schema (owner, pets) |Mariia Surmenok|Cat1|pointer -> Cat2|Parrot
(Edited: 2020-12-07) a) relative location - for each record store each attribute value in the order defined by its schema without specifying the name of the attribute. If the size can be variable, need to either specify the size before the item or use a delimiter.
Example for schema (name, student id, address): |Mariia Surmenok|13711111|Redwood City,CA
b) embedded identification: store the attribute type and name before the attribute value [VARCHAR][NAME][DAVID][INT][PHONENUMBER][999999]|
c) store multivalued attributes such that the first is stored in a record but for the rest, the pointer is used pointing to another location with the remaining values For example, pets names can be multivalued attributes if there are multiple pets. Here's the schema (owner, pets) |Mariia Surmenok|Cat1|pointer -> Cat2|Parrot
Group 1: David Bui, Mariia Surmenok
<u>Question 1</u>
----
a) relative location - for each record store each attribute value in the order defined by its schema without specifying the name of the attribute. If the size can be variable, need to either specify the size before the item or use a delimiter.
Example for schema (name, student id, address):
|Mariia Surmenok|13711111|Redwood City,CA
----
b) embedded identification: store the attribute type and name before the attribute value
[VARCHAR][NAME][DAVID][INT][PHONENUMBER][999999]|
----
c) store multivalued attributes such that the first is stored in a record but for the rest, the pointer is used pointing to another location with the remaining values
For example, pets names can be multivalued attributes if there are multiple pets.
Here's the schema (owner, pets)
|Mariia Surmenok|Cat1|pointer -> Cat2|Parrot
Group 1 Members: Mariia Surmenok, David Bui
Question 2:
Last SID digit = 3 and 3 + 1 = 4 * 1024 bytes = 4096 bytes
(2,000,000 tuples / 8 tuples/block) 1 block 4096 bytes
= 1,024,000,000 bytes
2,000,000 tuples / 8 tuples/block
= 250000 blocks
a) 1,024,000,000 bytes or 250,000 blocks
b) 16 byte key + 8 byte record = 24 bytes/block
4096 bytes / 24 bytes/block = 170.6
= 171 index records per block
c) 2,000,000 tuples / 171 records/block = 11695.9064327
= 11,696 blocks
Or 11696 * 4096
= 47906816 bytes
(Edited: 2020-12-07) Group 1 Members: Mariia Surmenok, David Bui
Question 2:
Last SID digit = 3 and 3 + 1 = 4 * 1024 bytes = 4096 bytes
(2,000,000 tuples / 8 tuples/block) * 1 block * 4096 bytes
= 1,024,000,000 bytes
2,000,000 tuples / 8 tuples/block
= 250000 blocks
a) 1,024,000,000 bytes or 250,000 blocks
b) 16 byte key + 8 byte record = 24 bytes/block
4096 bytes / 24 bytes/block = 170.6
= 171 index records per block
c) 2,000,000 tuples / 171 records/block = 11695.9064327
= 11,696 blocks
Or 11696 * 4096
= 47906816 bytes
Group 2 Members: Zach Tom, Aniruddha Mallya
Problem 3:
(a) Inverted file: maps content to its location within a database file, in a document or
in a set of documents. With an inverted file, you only need the space to write one
database address to store an additional index record with the same key value. Ex:
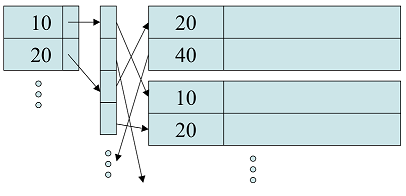
(b) Δ-list: if you have a sequence a0 < a1 < a2<...< an, then b0 = a0, bi+1 = ai+1 − ai
is a sequence of positive integers generally of smaller size than the original sequence.
The bi's are called Δ-lists and can be used to reconstruct the original ai's.
(c) Gap-compression: the process of writing posting lists using a Δ-list that is written
using a code like a γ-code, where γ-codes code a value bi with bi's length-1 in unary
using 0's followed by bi in binary. Ex: 5 would be encoded as 00101, 16 would be encoded
as 000010000.
(Edited: 2020-12-07) Group 2 Members: Zach Tom, Aniruddha Mallya
Problem 3:
(a) Inverted file: maps content to its location within a database file, in a document or
in a set of documents. With an inverted file, you only need the space to write one
database address to store an additional index record with the same key value. Ex:
((resource:SecondaryIndirection.png|Resource Description for SecondaryIndirection.png))
(b) Δ-list: if you have a sequence a0 < a1 < a2<...< an, then b0 = a0, bi+1 = ai+1 − ai
is a sequence of positive integers generally of smaller size than the original sequence.
The bi's are called Δ-lists and can be used to reconstruct the original ai's.
(c) Gap-compression: the process of writing posting lists using a Δ-list that is written
using a code like a γ-code, where γ-codes code a value bi with bi's length-1 in unary
using 0's followed by bi in binary. Ex: 5 would be encoded as 00101, 16 would be encoded
as 000010000.
Question 7.
- Log Structured Merge trees:
Data structure that is used to store index files in multiple tiers. When a partition is
written to disk, its index file is created and stored at tier 0. If there are (M-1) index
files at tier n then they are merged using the merge sort algorithm to create a new index
file at tier (n+1).
- Stable storage:
It is a policy that ensures when we write to disk, we will get a sector which is
correctly written, or that any data that was in the sector before the write can be safely
recovered.
- Raid level 4:
It is a disk failure scheme that uses parity blocks to check for data integrity. Every
ith block on the parity disk contains the parities of the data in the ith block of N data
disks. If the parity disk fails, it is recomputed and replaced. If the data disk fails
then it is recovered based on the other data blocks and the respective parity block.
Group members: Niraj Pandkar, Shreya Bhajikhaye
(Edited: 2020-12-07) Question 7.
1. Log Structured Merge trees:
Data structure that is used to store index files in multiple tiers. When a partition is
written to disk, its index file is created and stored at tier 0. If there are (M-1) index
files at tier n then they are merged using the merge sort algorithm to create a new index
file at tier (n+1).
2. Stable storage:
It is a policy that ensures when we write to disk, we will get a sector which is
correctly written, or that any data that was in the sector before the write can be safely
recovered.
3. Raid level 4:
It is a disk failure scheme that uses parity blocks to check for data integrity. Every
ith block on the parity disk contains the parities of the data in the ith block of N data
disks. If the parity disk fails, it is recomputed and replaced. If the data disk fails
then it is recovered based on the other data blocks and the respective parity block.
Group members: Niraj Pandkar, Shreya Bhajikhaye
GROUP 4: Niraj Pandkar, Shreya Bhajikhaye
<u>Question 8</u>
INSERT INTO employee VALUES (1, 'David', 'Male', 5000, 'Sales'), (2, 'Jim', 'Female', 6000, 'HR'), (3, 'Kate', 'Female', 7500, 'IT'), (4, 'Will', 'Male', 6500, 'Marketing'), (5, 'Shane', 'Female', 5500, 'Finance'), (6, 'Shed', 'Male', 8000, 'Sales'), (7, 'Vik', 'Male', 7200, 'HR'), (8, 'Vince', 'Female', 6600, 'IT'), (9, 'Jane', 'Female', 5400, 'Marketing'), (10, 'Laura', 'Female', 6300, 'Finance'), (11, 'Mac', 'Male', 5700, 'Sales'), (12, 'Pat', 'Male', 7000, 'HR'), (13, 'Julie', 'Female', 7100, 'IT'), (14, 'Elice', 'Female', 6800,'Marketing'), (15, 'Wayne', 'Male', 5000, 'Finance')
INSERT INTO employee VALUES (1, 'David', 'Male', 5000, 'Sales'), (2, 'Jim', 'Female', 6000, 'HR'), (3, 'Kate', 'Female', 7500, 'IT'), (4, 'Will', 'Male', 6500, 'Marketing'), (5, 'Shane', 'Female', 5500, 'Finance'), (6, 'Shed', 'Male', 8000, 'Sales'), (7, 'Vik', 'Male', 7200, 'HR'), (8, 'Vince', 'Female', 6600, 'IT'), (9, 'Jane', 'Female', 5400, 'Marketing'), (10, 'Laura', 'Female', 6300, 'Finance'), (11, 'Mac', 'Male', 5700, 'Sales'), (12, 'Pat', 'Male', 7000, 'HR'), (13, 'Julie', 'Female', 7100, 'IT'), (14, 'Elice', 'Female', 6800,'Marketing'), (15, 'Wayne', 'Male', 5000, 'Finance')
SELECT coalesce (department, 'All Departments') AS Department,
sum(salary) as Salary_Sum
FROM employee
GROUP BY ROLLUP (department)
| Department | Salary Sum |
|---|---|
| Finance | 16800 |
| HR | 20200 |
| IT | 21200 |
| Marketing | 18700 |
| Sales | 18700 |
| All Departments | 95600 |
- ROLLUP operators let you extend the functionality of GROUP BY clauses by calculating subtotals and grand totals for a set of columns. The CUBE operator is similar in functionality to the ROLLUP operator; however, the CUBE operator can calculate subtotals and grand totals for all permutations of the columns specified in it.
- ROLLUP operator generates aggregated results for the selected columns in a hierarchical way. On the other hand, CUBE generates a aggregated result that contains all the possible combinations for the selected columns.
GROUP 4: Niraj Pandkar, Shreya Bhajikhaye
<u>Question 8</u>
----
INSERT INTO employee
VALUES
(1, 'David', 'Male', 5000, 'Sales'),
(2, 'Jim', 'Female', 6000, 'HR'),
(3, 'Kate', 'Female', 7500, 'IT'),
(4, 'Will', 'Male', 6500, 'Marketing'),
(5, 'Shane', 'Female', 5500, 'Finance'),
(6, 'Shed', 'Male', 8000, 'Sales'),
(7, 'Vik', 'Male', 7200, 'HR'),
(8, 'Vince', 'Female', 6600, 'IT'),
(9, 'Jane', 'Female', 5400, 'Marketing'),
(10, 'Laura', 'Female', 6300, 'Finance'),
(11, 'Mac', 'Male', 5700, 'Sales'),
(12, 'Pat', 'Male', 7000, 'HR'),
(13, 'Julie', 'Female', 7100, 'IT'),
(14, 'Elice', 'Female', 6800,'Marketing'),
(15, 'Wayne', 'Male', 5000, 'Finance')
SELECT coalesce (department, 'All Departments') AS Department,
sum(salary) as Salary_Sum
FROM employee
GROUP BY ROLLUP (department)
{|
|-
! Department !! Salary Sum
|-
| Finance || 16800
|-
| HR || 20200
|-
| IT || 21200
|-
| Marketing || 18700
|-
| Sales || 18700
|-
| All Departments || 95600
|}
* ROLLUP operators let you extend the functionality of GROUP BY clauses by calculating subtotals and grand totals for a set of columns. The CUBE operator is similar in functionality to the ROLLUP operator; however, the CUBE operator can calculate subtotals and grand totals for all permutations of the columns specified in it.
* ROLLUP operator generates aggregated results for the selected columns in a hierarchical way. On the other hand, CUBE generates a aggregated result that contains all the possible combinations for the selected columns.
Mustafa Yesilyurt, Sida Zhong
- Divide the total memory blocks B in the relation we wish to sort into blocks of size M (there will be M-1 of these)
The first pass of this algorithm involves sorting each of these M-1 blocks. The second pass is where we will remove the
duplicates. Say we have the following example:
Block 1 | Block 2 | Block 3
[1, 2, 3, 4] [2, 3, 3, 4] [2, 2, 2, 3]
B1 | B2 | B3
Iteration 1: 1 | 2 | 2 // output 1; only iterate B1's pointer because it is the smallest Iteration 2: 2 | 2 | 2 // output 2; iterate every pointer because they are all equal Iteration 3: 3 | 3 | 2 // disregard B3's current value by iterating its pointer Iteration 4: 3 | 3 | 2 // same problem; need to iterate B3 Iteration 5: 3 | 3 | 3 // output 3; iterate every pointer because they are all equal Iteration 6: 4 | 3 | null // disregard B2''s current value by iterating its pointer Iteration 7: 4 | 4 | null // output 4; iterate every pointer because they are all equal Iteration 8: all done
Iteration 1: 1 | 2 | 2 // output 1; only iterate B1's pointer because it is the smallest Iteration 2: 2 | 2 | 2 // output 2; iterate every pointer because they are all equal Iteration 3: 3 | 3 | 2 // disregard B3's current value by iterating its pointer Iteration 4: 3 | 3 | 2 // same problem; need to iterate B3 Iteration 5: 3 | 3 | 3 // output 3; iterate every pointer because they are all equal Iteration 6: 4 | 3 | null // disregard B2''s current value by iterating its pointer Iteration 7: 4 | 4 | null // output 4; iterate every pointer because they are all equal Iteration 8: all done
output buffer: 1 -> 2 -> 3 -> 4
Let's assume our output buffer can only store 1 value at a time.
We take the first item from each of the M-1 blocks and compare them, outputting the smallest one and iterating the
pointer to that block. So after Iteration 1 is complete (in which we output 1), B1's pointer will point to index 1
(with value 2) while B2 and B3 will still both point to index 0 (each with value 2). With iteration 2, we output 2
and iterate all of the pointers (B1 at index 2, B2 at index 1, B3 at index 1). Since B3 still points to the value 2,
we disregard it, effectively removing the duplicate value. We continue iterating the pointer until it has no more
values or it is of equal value as the other pointers and we then repeat the output process.
We can estimate the I/O operation count to be the number of items per block plus the number of duplicates found across
all M-1 blocks.
(Edited: 2020-12-07) Mustafa Yesilyurt, Sida Zhong
6. Divide the total memory blocks B in the relation we wish to sort into blocks of size M (there will be M-1 of these)
The first pass of this algorithm involves sorting each of these M-1 blocks. The second pass is where we will remove the
duplicates. Say we have the following example:
Block 1 | Block 2 | Block 3
[1, 2, 3, 4] [2, 3, 3, 4] [2, 2, 2, 3]
B1 | B2 | B3
------------------------------
Iteration 1: 1 | 2 | 2 // output 1; only iterate B1's pointer because it is the smallest
Iteration 2: 2 | 2 | 2 // output 2; iterate every pointer because they are all equal
Iteration 3: 3 | 3 | 2 // disregard B3's current value by iterating its pointer
Iteration 4: 3 | 3 | 2 // same problem; need to iterate B3
Iteration 5: 3 | 3 | 3 // output 3; iterate every pointer because they are all equal
Iteration 6: 4 | 3 | null // disregard B2''s current value by iterating its pointer
Iteration 7: 4 | 4 | null // output 4; iterate every pointer because they are all equal
Iteration 8: all done
output buffer: 1 -> 2 -> 3 -> 4
Let's assume our output buffer can only store 1 value at a time.
We take the first item from each of the M-1 blocks and compare them, outputting the smallest one and iterating the
pointer to that block. So after Iteration 1 is complete (in which we output 1), B1's pointer will point to index 1
(with value 2) while B2 and B3 will still both point to index 0 (each with value 2). With iteration 2, we output 2
and iterate all of the pointers (B1 at index 2, B2 at index 1, B3 at index 1). Since B3 still points to the value 2,
we disregard it, effectively removing the duplicate value. We continue iterating the pointer until it has no more
values or it is of equal value as the other pointers and we then repeat the output process.
We can estimate the I/O operation count to be the number of items per block plus the number of duplicates found across
all M-1 blocks.
Mustafa Yesilyurt, Sida Zhong
- Show step-by-step (with intermediate drawings) what would happen if you inserted 14 + the fifth digit of your student ID into the B-tree
A fantastic example with propagation is on the Oct 21 Lectures
Mustafa's ID's fifth digit = 7
Sida's ID's fifth digit = 3
We will use 7 + 3 = 10 --> 14 + 10 = 24 // THIS DOES NOT CAUSE PROPAGATION.
insert 24 is the simplest case, just insert the 4th block of layer3, between 23 and 29.
The more complicated situation is to insert “14”, There will be 3 new blocks generated.
The newly generated tree looks like this
{13|31|-}
/ | \
/ | \
{7|-|-} {17|23|-} {43|-|-}
/ \ / | \ / \ {2|3|5} {7|11|-} {13|14|-} {17|19|-} {23|29|-} {31|37|41} {43,47}
(Edited: 2020-12-07) / \ / | \ / \ {2|3|5} {7|11|-} {13|14|-} {17|19|-} {23|29|-} {31|37|41} {43,47}
Mustafa Yesilyurt, Sida Zhong
5. Show step-by-step (with intermediate drawings) what would happen if you inserted 14 + the fifth digit of your student ID into the B-tree
A fantastic example with propagation is on the Oct 21 Lectures
Mustafa's ID's fifth digit = 7
Sida's ID's fifth digit = 3
We will use 7 + 3 = 10 --> 14 + 10 = 24 // THIS DOES NOT CAUSE PROPAGATION.
insert 24 is the simplest case, just insert the 4th block of layer3, between 23 and 29.
The more complicated situation is to insert “14”, There will be 3 new blocks generated.
The newly generated tree looks like this
{13|31|-}
- - - -
/ | \
{7|-|-} {17|23|-} {43|-|-}
- - - - - - - - - - - -
/ \ / | \ / \
{2|3|5} {7|11|-} {13|14|-} {17|19|-} {23|29|-} {31|37|41} {43,47}
(c) 2026 Yioop - PHP Search Engine