
2021-05-17

Practice Final Thread .
Please post your solutions to the practice final problems to this thread.
Best,
Chris
Please post your solutions to the practice final problems to this thread.
Best,
Chris
Team: Justin and Michaela
Question 6: Explain what kind of incremental updates logarithmic merging is
a suitable algorithm for. Explain how this algorithm works.
partitions
1 2 3 4 5
* insert partition
** insert partition (duplicate)
* merge and increment
* * insert partition
** * insert partition (duplicate)
** merge and increment (duplicate)
* merge and increment
Incremental updates that are suitable for logarithmic merging is when we have little amount of ram and enough disk space to write to. Merging Indexes are also more suitable towards updates and are not as efficient with frequent deletions. When the indexing process runs out of memory, it writes it make an on disk partition with the label 1. Any existing duplicated labels are merged and the resulting merged index gets a label +1. This process is repeated until there are not duplicate labeled index partitions.
- Unordered list item We can speed up the merging process by looking ahead and merging together. If you see that you will have to merge twice in a row, you can merge all of the three partitions in one operation.
<nowiki>
Team: Justin and Michaela
Question 6: Explain what kind of incremental updates logarithmic merging is
a suitable algorithm for. Explain how this algorithm works.
partitions
1 2 3 4 5
* insert partition
** insert partition (duplicate)
* merge and increment
* * insert partition
** * insert partition (duplicate)
** merge and increment (duplicate)
* merge and increment
</nowiki>
Incremental updates that are suitable for logarithmic merging is when we have little amount of ram and enough disk space to write to. Merging Indexes are also more suitable towards updates and are not as efficient with frequent deletions. When the indexing process runs out of memory, it writes it make an on disk partition with the label 1. Any existing duplicated labels are merged and the resulting merged index gets a label +1. This process is repeated until there are not duplicate labeled index partitions.
* Unordered list item
We can speed up the merging process by looking ahead and merging together. If you see that you will have to merge twice in a row, you can merge all of the three partitions in one operation.
Team: Kevin and Sriramm
Question 9. Explain how hub and authority scores are calculated in HITS
a. To compute the HITS we compute 2 scores, the authority score and the hub score for each site.
b. Authority score is the sum of the hubs linking to a site and Hub score is the measure of how good the authorities linked from this site are. There are k rounds in total. We iterate through k until the auth scores and the hub scores for the current and the previous round are lesser than a threshold.
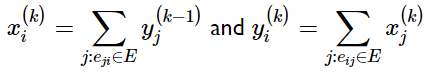
c. We initialize the auth score and the hub score to 1. For the next rounds, we calculate the hub score by the sum of auth score of the current round and the auth score by the sum of the hub scores of the previous rounds. We do not add all of the authority scores to find the hub score; instead, we add the authority scores of the links that are relevant to our query term.
d. We iterate through k until the auth scores and the hub scores for the current and the previous round are lesser than a threshold.
(Edited: 2021-05-17)
Team: Kevin and Sriramm
Question 9. Explain how hub and authority scores are calculated in HITS
a. To compute the HITS we compute 2 scores, the authority score and the hub score for each site.
b. Authority score is the sum of the hubs linking to a site and Hub score is the measure of how good the authorities linked from this site are. There are k rounds in total. We iterate through k until the auth scores and the hub scores for the current and the previous round are lesser than a threshold.
((resource:Screenshot 2021-05-17 172346.png|Resource Description for Screenshot 2021-05-17 172346.png))
c. We initialize the auth score and the hub score to 1. For the next rounds, we calculate the hub score by the sum of auth score of the current round and the auth score by the sum of the hub scores of the previous rounds. We do not add all of the authority scores to find the hub score; instead, we add the authority scores of the links that are relevant to our query term.
d. We iterate through k until the auth scores and the hub scores for the current and the previous round are lesser than a threshold.
Team: Srilekha Nune and Austin Anderson
Question 3:Express the following as region algebra queries: (a) Your first name within 10 terms of your last name. (b) Your birthday in a <birthdate></birthdate> tags before the phrase "wins the lottery".
([10]△[9]△[8]△[7]△[6]△[5]△[4]△[3]△[2]△[1]) ◁ ("FIRSTNAME" … "LASTNAME")
"wins the lottery" … (("<birthdate>" … "</birthdate>") ▷ "DATE_OF_BIRTH")
(Edited: 2021-05-17) Team: Srilekha Nune and Austin Anderson
Question 3:Express the following as region algebra queries: (a) Your first name within 10 terms of your last name. (b) Your birthday in a <birthdate></birthdate> tags before the phrase "wins the lottery".
([10]△[9]△[8]△[7]△[6]△[5]△[4]△[3]△[2]△[1]) ◁ ("FIRSTNAME" … "LASTNAME")
"wins the lottery" … (("<birthdate>" … "</birthdate>") ▷ "DATE_OF_BIRTH")
Team: Devangi and Sudhin
Question 1: Prove 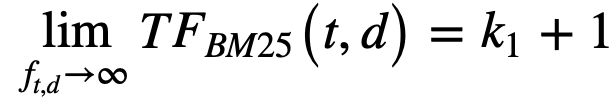 . Briefly explain the Maxscore heuristic as used in document at a time query processing.
. Briefly explain the Maxscore heuristic as used in document at a time query processing.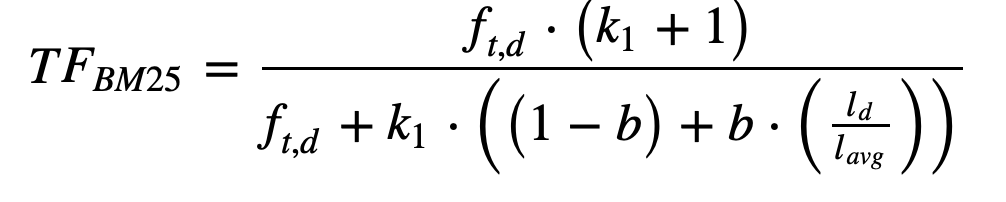
. Briefly explain the Maxscore heuristic as used in document at a time query processing.We have,
By L'Hopital's rule for limits, take derivatives of the numerator and denominator with respect to f_t,d and we get the value k1+1 as the value of the limit.
MaxScore Heuristic =>
(Edited: 2021-05-17) Suppose the user who entered the Q query is interested in the top k = n search results. Q = < "sport", "rugby", "football"> The terms' corresponding MaxScore values and result's scores are compared to remove some terms from the DocumentAtATime heap (managing the set of terms and set of top-k documents) via when computing scores for more and more documents. Removal is done when documents contain only one or more initial terms that wouldnt make it to the top n search results (such as only containing "sport" but no "rugby"). We may look at its posting only if we find a result that contains the other query terms.Even though MAXSCORE removes some terms from the heap, it still uses them for scoring. This is done by maintaining two data structures, one for terms that are still on the heap and the other for terms that have been removed from the heap.
Team: Devangi and Sudhin
Question 1: Prove ((resource:Screen Shot 2021-05-17 at 2.03.48 PM.png|Resource Description for Screen Shot 2021-05-17 at 2.03.48 PM.png)). Briefly explain the Maxscore heuristic as used in document at a time query processing.
We have, ((resource:Screen Shot 2021-05-17 at 2.03.39 PM.png|Resource Description for Screen Shot 2021-05-17 at 2.03.39 PM.png))
By L'Hopital's rule for limits, take derivatives of the numerator and denominator with respect to f_t,d and we get the value k1+1 as the value of the limit.
MaxScore Heuristic =>
Suppose the user who entered the Q query is interested in the top k = n search results.
Q = < "sport", "rugby", "football">
The terms' corresponding MaxScore values and result's scores are compared to remove some terms from the DocumentAtATime heap
(managing the set of terms and set of top-k documents) via when computing scores for more and more documents. Removal is done when documents contain only one or more initial terms that wouldnt make it to the top n search results (such as only containing "sport" but no "rugby").
We may look at its posting only if we find a result that contains the other query terms.Even though MAXSCORE removes some terms from the heap,
it still uses them for scoring. This is done by maintaining two data structures, one for terms that are still on
the heap and the other for terms that have been removed from the heap.
By Paaras Chand, Vaishnavi Nagireddy
Problem: 7
Distinguish intra-query and inter-query parallelism as far as information retrieval goes. What bottlenecks exists to intra-query parallelism if partition-by-document is used.
Inter-query parallelism:
By creating n replicas of the index and assigning each replica to a separate node, we can realize an n-fold increase of the search engine’s service rate without affecting the time required to process a single query.
This type of parallelism is referred to as inter-query parallelism, as multiple queries can be processed in parallel but each individual query is processed sequentially.
Intra-query parallelism: By splitting the index into n parts, each node works only on its own small part of the index. This approach is called intra-query parallelism. Each query is processed by multiple servers in parallel. This improves the engine’s service rate as well as the average time per query.
Bottlenecks:
Document partitioning works best when the index data on the individual nodes can be stored in main memory.
suppose, queries were on average 3 words and we want the search engine to handle 100 queries per second. Due to queueing effects, we cannot achieve a utilization of more than 50% typically, without experiencing latency jumps.
So a query load of 100qps translates to a required service rate of at least 200 qps. For 3 word queries, this translates to at least 600 random access operations per second.
Assuming an average disk latency of 10ms, a single hard disk drive cannot perform more than 100 random access operations per second, one sixth of what we need on each of our nodes.Adding more machines doesn't affect the minimum of what each machine must do, so this is a bottleneck for the document partitioning approach.
(Edited: 2021-05-17) By Paaras Chand, Vaishnavi Nagireddy
Problem: 7
Distinguish intra-query and inter-query parallelism as far as information retrieval goes. What bottlenecks exists to intra-query parallelism if partition-by-document is used.
Inter-query parallelism:
By creating n replicas of the index and assigning each replica to a separate node, we can realize an n-fold increase of the search engine’s service rate without affecting the time required to process a single query.
This type of parallelism is referred to as inter-query parallelism, as multiple queries can be processed in parallel but each individual query is processed sequentially.
Intra-query parallelism:
By splitting the index into n parts, each node works only on its own small part of the index. This approach is called intra-query parallelism. Each query is processed by multiple servers in parallel. This improves the engine’s service rate as well as the average time per query.
Bottlenecks:
Document partitioning works best when the index data on the individual nodes can be stored in main memory.
suppose, queries were on average 3 words and we want the search engine to handle 100 queries per second. Due to queueing effects, we cannot achieve a utilization of more than 50% typically, without experiencing latency jumps.
So a query load of 100qps translates to a required service rate of at least 200 qps. For 3 word queries, this translates to at least 600 random access operations per second.
Assuming an average disk latency of 10ms, a single hard disk drive cannot perform more than 100 random access operations per second, one sixth of what we need on each of our nodes.Adding more machines doesn't affect the minimum of what each machine must do, so this is a bottleneck for the document partitioning approach.
Question 10
Paaras Chand, Vaishnavi Nagireddy
Batch filtering refers to a process where incoming documents are accumulated, indexed, and ranked. This process is repeated as more documents are added. It is useful in situations where the delay (to load the accumulators) is acceptable. Example: N = 1,000 batch size = 100 10 total batches calculate metrics (p@k, ap, rel) for each batch separately When using batch processing, P@k is less meaningful because the number of relevant documents for each batch will vary, yet k remains fixed. Instead, we can use aggregate P@k which utilizes a threshold with our scoring function. This way we’re not just return the top n number of documents from each batch, but those which are above a certain threshold value. A carefully chosen threshold value can also limit the number of documents (k = pN). Example: N = 1000 threshold=N-X=1000-100=900 -> Only 100 documents will have a score over 900 For each batch store documents with score > threshold, Calculate precision for each batch: Precision = percentage of the result that is relevant = [relevant AND result]/result Aggregate P@100 score = average(precision for each batch)
(Edited: 2021-05-17) Paaras Chand, Vaishnavi Nagireddy
Batch filtering refers to a process where incoming documents are accumulated, indexed, and ranked. This process is repeated as more documents are added. It is useful in situations where the delay (to load the accumulators) is acceptable. Example: N = 1,000 batch size = 100 10 total batches calculate metrics (p@k, ap, rel) for each batch separately When using batch processing, P@k is less meaningful because the number of relevant documents for each batch will vary, yet k remains fixed. Instead, we can use aggregate P@k which utilizes a threshold with our scoring function. This way we’re not just return the top n number of documents from each batch, but those which are above a certain threshold value. A carefully chosen threshold value can also limit the number of documents (k = pN). Example: N = 1000 threshold=N-X=1000-100=900 -> Only 100 documents will have a score over 900 For each batch store documents with score > threshold, Calculate precision for each batch: Precision = percentage of the result that is relevant = [relevant AND result]/result Aggregate P@100 score = average(precision for each batch)
Question 10
<br>Paaras Chand, Vaishnavi Nagireddy
<br><br>
Batch filtering refers to a process where incoming documents are accumulated, indexed, and ranked. This process is repeated as more documents are added. It is useful in situations where the delay (to load the accumulators) is acceptable.
<nowiki>
Example:
N = 1,000
batch size = 100
10 total batches
calculate metrics (p@k, ap, rel) for each batch separately
</nowiki>
When using batch processing, P@k is less meaningful because the number of relevant documents for each batch will vary, yet k remains fixed. Instead, we can use aggregate P@k which utilizes a threshold with our scoring function. This way we’re not just return the top n number of documents from each batch, but those which are above a certain threshold value. A carefully chosen threshold value can also limit the number of documents (k = pN).
<nowiki>
Example:
N = 1000
threshold=N-X=1000-100=900
-> Only 100 documents will have a score over 900
For each batch store documents with score > threshold,
Calculate precision for each batch:
Precision = percentage of the result that is relevant = [relevant AND result]/result
Aggregate P@100 score = average(precision for each batch)
</nowiki>
Question 10: What is Batch filtering? What is aggregate P@k?
Team: Justin and Michaela
Batch filtering is when there is a queue of documents and after a set period of time, the documents are are filtered according to whether they match a given topic. A query is used to determine the relvance to a topic and score each document in batch.
Aggregate P@k measures the number of relavant documents accross all of the batches. A threshhold is determined and each document is thought to be relevant if they score above that threshold. We calculate the precision of each batch by diving the human determined relevant documents that meet the threshold over the total documents that are over the threshold. We do that for every batch and then the average precision of the batches is the aggregate P@k.
the threshold should be picked so k = pN
Question 10: What is Batch filtering? What is aggregate P@k?
Team: Justin and Michaela
Batch filtering is when there is a queue of documents and after a set period of time, the documents are are filtered according to whether they match a given topic. A query is used to determine the relvance to a topic and score each document in batch.
Aggregate P@k measures the number of relavant documents accross all of the batches. A threshhold is determined and each document is thought to be relevant if they score above that threshold. We calculate the precision of each batch by diving the human determined relevant documents that meet the threshold over the total documents that are over the threshold. We do that for every batch and then the average precision of the batches is the aggregate P@k.
the threshold should be picked so k = pN
Mustafa Yesilyurt, Pranjali Bansod
Give an example of a parametric and of a non-parametric code suitable for GAP compression. Briefly explain and give an example of vByte and Simple-9.
A non-parametric code for gap compression: Gamma-coding
In Gamma codes there are 2 parts of a code - The selector and the body
The selector contains the number of bits required for the binary representation of a number. It is written in unary.
The body is the binary representation of the number that is being encoded.
We drop the 1 from the end of the selector and append the body.
Example:
We want to encode 5
The selector will be 001, since 5 can be represented in 3 bits as 101.
The body will be the binary encoding of 5, that is 101
selector ++ body = 001 101
We drop the 1 from the end of the selector so the final code word is 00101
In Gamma codes there are 2 parts of a code - The selector and the body
The selector contains the number of bits required for the binary representation of a number. It is written in unary.
The body is the binary representation of the number that is being encoded.
We drop the 1 from the end of the selector and append the body.
Example:
We want to encode 5
The selector will be 001, since 5 can be represented in 3 bits as 101.
The body will be the binary encoding of 5, that is 101
selector ++ body = 001 101
We drop the 1 from the end of the selector so the final code word is 00101
A parametric code for gap compression: LLRUN
We group similarly-sized gaps ("delta-values") into these codewords (a.k.a "buckets" or "bins") generated for Huffman
coding. "Similarly-sized" usually means within the same power of two, i.e. a bucket will contain the gaps of values
[2^j, (2^(j+1))-1]. Essentially, all the gaps that share the same codeword share the same bucket. Once we have the
Huffman tree of codewords built, we use the Huffman coding of a bucket's codeword (a binary sequence) to reference
the bucket. To reference a specific gap inside the bucket, we append the gap's binary representation to the end of
the bucket's codeword's Huffman coding. This combination of bucket representation and gap representation forms LLRUN.
We group similarly-sized gaps ("delta-values") into these codewords (a.k.a "buckets" or "bins") generated for Huffman
coding. "Similarly-sized" usually means within the same power of two, i.e. a bucket will contain the gaps of values
[2^j, (2^(j+1))-1]. Essentially, all the gaps that share the same codeword share the same bucket. Once we have the
Huffman tree of codewords built, we use the Huffman coding of a bucket's codeword (a binary sequence) to reference
the bucket. To reference a specific gap inside the bucket, we append the gap's binary representation to the end of
the bucket's codeword's Huffman coding. This combination of bucket representation and gap representation forms LLRUN.
vByte:
Out of 8 bits 1 bit is used to indicate if there is going to be a next byte representing a number or not.
The remaining 7 bits are used for representing the data itself.
Example:
The remaining 7 bits are used for representing the data itself.
Example:
So if want to encode 255 in vbyte:
255 requires 8 bits to represent. So, we will need 2 bytes to represent 255.
The representaion looks like below.
10000001 01111111
Explanation for 10000001:
The representaion looks like below.
10000001 01111111
Explanation for 10000001:
The first 1 is to indicate that there is one more byte needed for representing 255
The last 1 is the MSB of binary representation of 255.
The last 1 is the MSB of binary representation of 255.
Explanation for 01111111:
The first 0 is to indicate that there are no more bytes required to represent 255.
The remaining 1s are the remaining 7 bits are 7 bits from binary representation of 255.
The first 0 is to indicate that there are no more bytes required to represent 255.
The remaining 1s are the remaining 7 bits are 7 bits from binary representation of 255.
Simple-9:
Simple-9 is a simple word-aligned encoding method (32 bits total) made up of two parts: a selector and a body.
The latter 28 bits are used for splitting into equal-sized chunks while the initial 4 bits form a selector that
indicates which split is used within the current word. There are 9 different ways of splitting which explains why
the selector is 4 bits long and why the encoding scheme is called Simple-9.
Simple-9 is a simple word-aligned encoding method (32 bits total) made up of two parts: a selector and a body.
The latter 28 bits are used for splitting into equal-sized chunks while the initial 4 bits form a selector that
indicates which split is used within the current word. There are 9 different ways of splitting which explains why
the selector is 4 bits long and why the encoding scheme is called Simple-9.
Example:
Let's encode the sequence {225, 95, 383}
0010 011100001 001011111 101111111 U
The selector here is 0010 = 2, so we will be splitting into 3 groups of 9 bits each with an unused bit at the end.
011100001 is 225 represented by 9 bits, 001011111 is 95 in 9 bits, and 101111111 is 383 in 9 bits.
(Edited: 2021-05-17) Let's encode the sequence {225, 95, 383}
0010 011100001 001011111 101111111 U
The selector here is 0010 = 2, so we will be splitting into 3 groups of 9 bits each with an unused bit at the end.
011100001 is 225 represented by 9 bits, 001011111 is 95 in 9 bits, and 101111111 is 383 in 9 bits.
Mustafa Yesilyurt, Pranjali Bansod<br><br>
Give an example of a parametric and of a non-parametric code suitable for GAP compression. Briefly explain and give an example of vByte and Simple-9.<br><br>
A non-parametric code for gap compression: Gamma-coding<br><br>
In Gamma codes there are 2 parts of a code - The selector and the body<br>
The selector contains the number of bits required for the binary representation of a number. It is written in unary.<br>
The body is the binary representation of the number that is being encoded.<br>
We drop the 1 from the end of the selector and append the body.<br><br>
Example:<br>
We want to encode 5<br>
The selector will be 001, since 5 can be represented in 3 bits as 101.<br>
The body will be the binary encoding of 5, that is 101<br>
selector ++ body = 001 101<br>
We drop the 1 from the end of the selector so the final code word is 00101<br><br>
A parametric code for gap compression: LLRUN<br><br>
We group similarly-sized gaps ("delta-values") into these codewords (a.k.a "buckets" or "bins") generated for Huffman <br>
coding. "Similarly-sized" usually means within the same power of two, i.e. a bucket will contain the gaps of values <br>
[2^j, (2^(j+1))-1]. Essentially, all the gaps that share the same codeword share the same bucket. Once we have the <br>
Huffman tree of codewords built, we use the Huffman coding of a bucket's codeword (a binary sequence) to reference <br>
the bucket. To reference a specific gap inside the bucket, we append the gap's binary representation to the end of <br>
the bucket's codeword's Huffman coding. This combination of bucket representation and gap representation forms LLRUN.<br><br>
vByte:<br><br>
Out of 8 bits 1 bit is used to indicate if there is going to be a next byte representing a number or not. <br>
The remaining 7 bits are used for representing the data itself.<br><br>
Example:<br>
So if want to encode 255 in vbyte:<br>
255 requires 8 bits to represent. So, we will need 2 bytes to represent 255.<br>
The representaion looks like below.<br>
10000001 01111111<br>
<br>
Explanation for 10000001:<br>
The first 1 is to indicate that there is one more byte needed for representing 255<br>
The last 1 is the MSB of binary representation of 255.<br><br>
Explanation for 01111111:<br>
The first 0 is to indicate that there are no more bytes required to represent 255.<br>
The remaining 1s are the remaining 7 bits are 7 bits from binary representation of 255.<br><br>
Simple-9:<br>
<br>
Simple-9 is a simple word-aligned encoding method (32 bits total) made up of two parts: a selector and a body. <br>
The latter 28 bits are used for splitting into equal-sized chunks while the initial 4 bits form a selector that <br>
indicates which split is used within the current word. There are 9 different ways of splitting which explains why <br>
the selector is 4 bits long and why the encoding scheme is called Simple-9.<br><br>
Example:<br>
Let's encode the sequence {225, 95, 383}<br>
0010 011100001 001011111 101111111 U<br>
The selector here is 0010 = 2, so we will be splitting into 3 groups of 9 bits each with an unused bit at the end.<br>
011100001 is 225 represented by 9 bits, 001011111 is 95 in 9 bits, and 101111111 is 383 in 9 bits.
Team - 4: Vrinda and William
Q4. Give a concrete example involving your name of how a Canonical Huffman code might be written as a preamble to encoding a string.
Vrinda
Letter probabilities:
({'v'}, 1/6), ({'r'}, 1/6), ({'i'}, 1/6), ({'n'}, 1/6), ({'d'}, 1/6), ({'a'}, 1/6)

Preamble: ((‘v’, 000), (‘r’, 001), (‘i’, 010), (‘n’, 011), (‘d’, 1), , (‘a’, 11))
William:
Letter probabilities:
({'a'}, 1/7), ({'m'}, 1/7), ({'w'}, 1/7), ({'i'}, 2/7), ({'l'}, 2/7)
Combine {'a'} and {'m'}
({'w'}, 1/7), ({'i'}, 2/7), ({'l'}, 2/7), ({'a', 'm'}, 2/7)
Combine {'w'} and {'i'}
({'l'}, 2/7), ({'a', 'm'}, 2/7), ({'w', 'i'}, 3/7)
Combine {'l'} and {'a', 'm'}
({'w', 'i'}, 3/7), ({'l', 'a', 'm'}, 4/7)
Combine {'w', 'i'} and {'l', 'a', 'm'}
({'w', 'i', 'l', 'a', 'm'}, 1)

Preamble: ((‘w’, 00), (‘i’, 01), (‘l’, 10), (‘a’, 110), (‘m’, 111))
(Edited: 2021-05-17) Team - 4: Vrinda and William
Q4. Give a concrete example involving your name of how a Canonical Huffman code might be written as a preamble to encoding a string.
Vrinda
Letter probabilities:
({'v'}, 1/6), ({'r'}, 1/6), ({'i'}, 1/6), ({'n'}, 1/6), ({'d'}, 1/6), ({'a'}, 1/6)
((resource:Screen Shot 2021-05-17 at 2.32.29 PM.png|Resource Description for Screen Shot 2021-05-17 at 2.32.29 PM.png))
Preamble: ((‘v’, 000), (‘r’, 001), (‘i’, 010), (‘n’, 011), (‘d’, 1), , (‘a’, 11))
----
William:
Letter probabilities:
({'a'}, 1/7), ({'m'}, 1/7), ({'w'}, 1/7), ({'i'}, 2/7), ({'l'}, 2/7)
Combine {'a'} and {'m'}
({'w'}, 1/7), ({'i'}, 2/7), ({'l'}, 2/7), ({'a', 'm'}, 2/7)
Combine {'w'} and {'i'}
({'l'}, 2/7), ({'a', 'm'}, 2/7), ({'w', 'i'}, 3/7)
Combine {'l'} and {'a', 'm'}
({'w', 'i'}, 3/7), ({'l', 'a', 'm'}, 4/7)
Combine {'w', 'i'} and {'l', 'a', 'm'}
({'w', 'i', 'l', 'a', 'm'}, 1)
((resource:Screen Shot 2021-05-17 at 2.32.35 PM.png|Resource Description for Screen Shot 2021-05-17 at 2.32.35 PM.png))
Preamble: ((‘w’, 00), (‘i’, 01), (‘l’, 10), (‘a’, 110), (‘m’, 111))
(c) 2026 Yioop - PHP Search Engine