
2021-10-11

Practice Midterm Solutions .
Please post your problem solutions for the Practice Midterm to this thread.
Best,
Chris
Please post your problem solutions for the Practice Midterm to this thread.
Best,
Chris
Names: Madhujita Ambaskar, Rishabh Pandey
Solution for Q.2 
Names: Madhujita Ambaskar, Rishabh Pandey
Solution for Q.2 ((resource:WhatsApp Image 2021-10-11 at 4.18.07 PM.jpeg|Resource Description for WhatsApp Image 2021-10-11 at 4.18.07 PM.jpeg))
Names - Abhishek Vaid, Shashwat Kadam

Names - Abhishek Vaid, Shashwat Kadam
((resource:IMG-20211011-WA0001.jpg|Resource Description for IMG-20211011-WA0001.jpg))
Venkat Teja Golamaru
Venkata Sai Sathwik Nadella
Tarun Mourya Satveli
Question 6:

Question 9:
Venkat Teja Golamaru
Venkata Sai Sathwik Nadella
Tarun Mourya Satveli
Question 6:
((resource:WhatsApp Image 2021-10-11 at 4.49.26 PM.jpeg|Resource Description for WhatsApp Image 2021-10-11 at 4.49.26 PM.jpeg))
Question 9:
((resource:WhatsApp Image 2021-10-11 at 5.00.00 PM.jpeg|Resource Description for WhatsApp Image 2021-10-11 at 5.00.00 PM.jpeg))
Names: Madhujita Ambaskar, Rishabh Pandey. Solution for Q.10
Sometimes when we have a limited amount of data, we can divide that data into test set & training set. This can result in a small test set which in turn can result in the error in the accuracy of test measurements being larger. Due to these large errors, it might be difficult to compare two algorithms' performance.
Cross Validation solves this by splitting the data set into training and test data several times and in several different ways, performing measurements for each of these trials, and combining these measurements by computing an appropriate aggregation such as an average. Cross-validation can be either exhaustive or non-exhaustive.
One example for exhaustive cross validation is Leave-p-out cross validation where you cycle over all possible p-subsets of the data sets, train on the data excluding the p-subset, test on the p-subset.
One example of non exhaustive cross validation is Repeated Random Sub-sampling Validation where you randomly repeat m-times, choose a subset of size p as the test data set, train on the remaining data, test on this subset.
(Edited: 2021-10-11) Names: Madhujita Ambaskar, Rishabh Pandey. Solution for Q.10
Sometimes when we have a limited amount of data, we can divide that data into test set & training set. This can result in a small test set which in turn can result in the error in the accuracy of test measurements being larger. Due to these large errors, it might be difficult to compare two algorithms' performance.
Cross Validation solves this by splitting the data set into training and test data several times and in several different ways, performing measurements for each of these trials, and combining these measurements by computing an appropriate aggregation such as an average. Cross-validation can be either exhaustive or non-exhaustive.
One example for exhaustive cross validation is Leave-p-out cross validation where you cycle over all possible p-subsets of the data sets, train on the data excluding the p-subset, test on the p-subset.
One example of non exhaustive cross validation is Repeated Random Sub-sampling Validation where you randomly repeat m-times, choose a subset of size p as the test data set, train on the remaining data, test on this subset.
Names: Shashwat Kadam, Abhishek Vaid
Q.9}
from PIL import Image
import numpy as np
img = Image.open("foo.png") # read
img = img.rotate(90) # rotation
img = img.convert("L") # conversion
width, height = img.shape
img_arr = np.frombuffer(img.tobytes(), dtype=np.uint8)
img_arr = np.reshape(img_arr, (height, width))
(Edited: 2021-10-11) Names: Shashwat Kadam, Abhishek Vaid
Q.9}
from PIL import Image
import numpy as np
img = Image.open("foo.png") # read
img = img.rotate(90) # rotation
img = img.convert("L") # conversion
width, height = img.shape
img_arr = np.frombuffer(img.tobytes(), dtype=np.uint8)
img_arr = np.reshape(img_arr, (height, width))
Question 5 - Manasa Mananjaya and Prajna Gururaj Puranik
Write a Python function num_examples(n, k, epsilon, delta) which computes the number of training examples needed to PAC-learn an n-bit threshold function from a class of gradual threshold functions to within ε-error at least 1−δ fraction of the time.
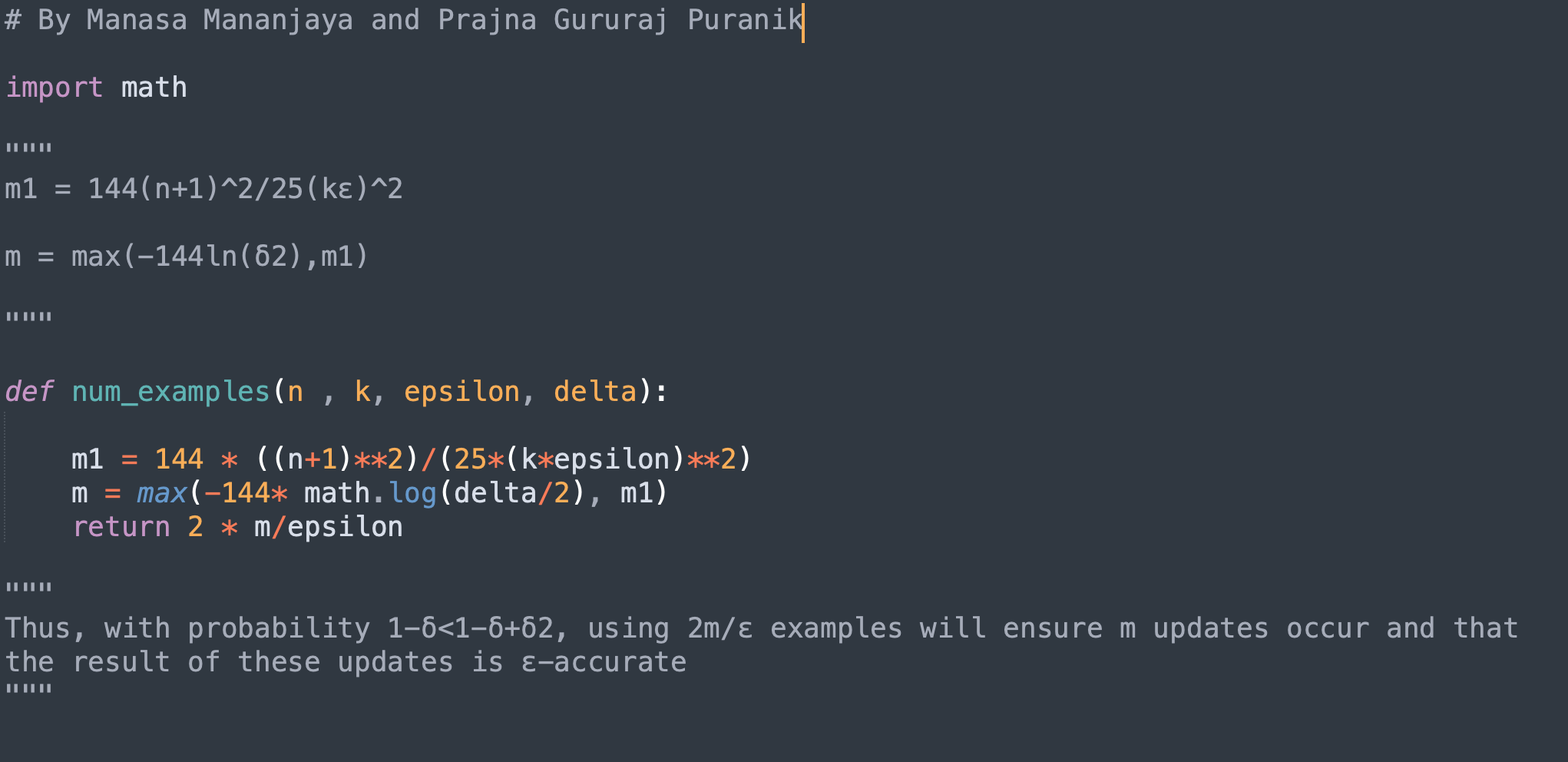
Question 5 - Manasa Mananjaya and Prajna Gururaj Puranik
<br/>
<br/>
Write a Python function num_examples(n, k, epsilon, delta) which computes the number of training examples needed to PAC-learn an n-bit threshold function from a class of gradual threshold functions to within ε-error at least 1−δ fraction of the time.
<br/>
((resource:Screen Shot 2021-10-11 at 4.40.11 PM.png|Resource Description for Screen Shot 2021-10-11 at 4.40.11 PM.png))
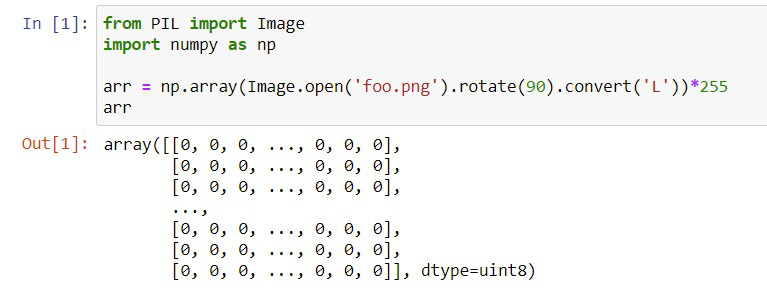
Names: Madhujita (MJ), Rishabh
Problem 9: Explain how to read in an image foo.png using Pillow, rotate 90 degrees, convert it to 1-byte grayscale, and then get the bytes into a 2D numpy array of the same dimensions as the original image.
We use the convert and reshape method here.
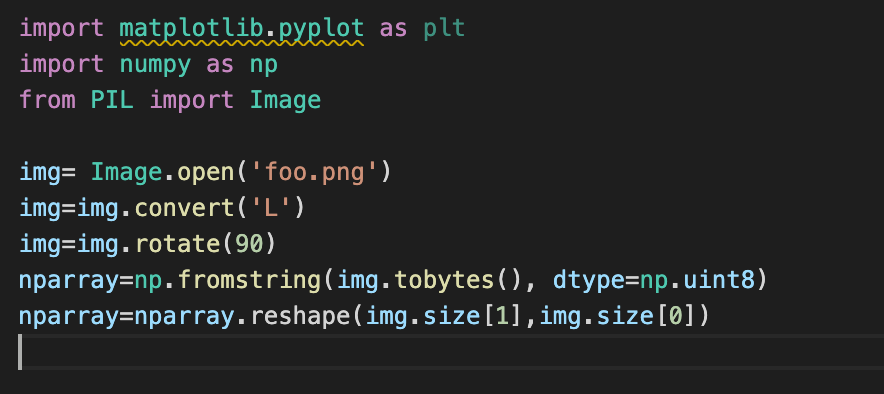
Names: Madhujita (MJ), Rishabh
Problem 9: Explain how to read in an image foo.png using Pillow, rotate 90 degrees, convert it to 1-byte grayscale, and then get the bytes into a 2D numpy array of the same dimensions as the original image.
We use the convert and reshape method here.
((resource:Screen Shot 2021-10-11 at 4.47.49 PM.png|Resource Description for Screen Shot 2021-10-11 at 4.47.49 PM.png))
Names: Pranjali Bansod and Lakshmi Prasanna Gorrepati
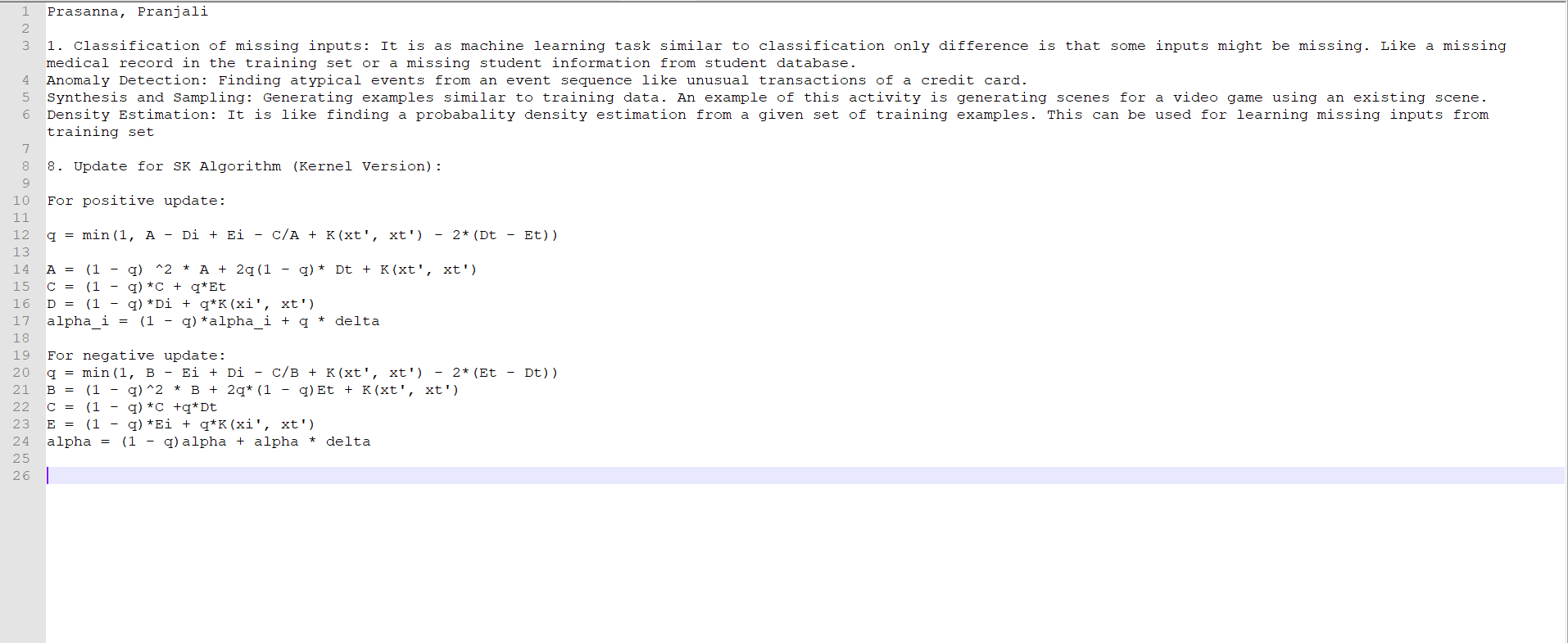
(Edited: 2021-10-25)
Names: Pranjali Bansod and Lakshmi Prasanna Gorrepati
((resource:Mid.png|Resource Description for Mid.png))
Names: Shashwat Kadam, Abhishek Vaid
Q.10}
Cross-Validation is a technique to estimate how well your training is performing before using the trained parameters on the testing data. We split the training data into training data and validation data, to calculate the performance metrics (e.g., accuracy, loss, etc.) on the validation data.
k-fold cross-validation:
- Split the training data into 'k' splits.
- Use one split for validation and the remaining splits for the training.
- Perform training and compute the metrics for the validation split. Accumulate the result in some array.
- Designate another split as validation data now and repeat from step 2.
Take the average of the metrics computed during the training and validation process. This will be the final metric for the training.
After every split performed the role of validation data, we say that exhaustive validation has happened.
If all the examples are NOT used at least once for validation, then the validation is inexhaustive.
(Edited: 2021-10-11) Names: Shashwat Kadam, Abhishek Vaid
Q.10}
Cross-Validation is a technique to estimate how well your training is performing before using the trained parameters on the testing data. We split the training data into training data and validation data, to calculate the performance metrics (e.g., accuracy, loss, etc.) on the validation data.
k-fold cross-validation:
# Split the training data into 'k' splits.
# Use one split for validation and the remaining splits for the training.
# Perform training and compute the metrics for the validation split. Accumulate the result in some array.
# Designate another split as validation data now and repeat from step 2.
Take the average of the metrics computed during the training and validation process. This will be the final metric for the training.
After every split performed the role of validation data, we say that exhaustive validation has happened.
If all the examples are NOT used at least once for validation, then the validation is inexhaustive.
(c) 2026 Yioop - PHP Search Engine