
2022-03-14

-- Damanpreet Kaur and Divyashree Jayaram
10) Fenestrate
For char 5 grams the word would be split into following terms-
.fene , fenes , enest, nestr, estra, strat, trate, rate.
Stopping - In IR systems stopwords are stripped from the query before doing an index look-up. These stopwords often include function words. Function words are words that have no well-defined meanings in and of themselves; rather, they modify words or indicate grammatical relationships.
The process of stopping is also applied to the corpus before the creation of the index.
Stopping helps to reduce index size and also decreases the query processing time.
For instance- A and B
It would be converted to A B
Stemming- It is the process of an IR system where objective is to reduce each term to its root form. for example - "runs" to match "running"
Potter stemmer rules
sses => ss
ies => I
ss => ss (Stop execution)
s =>
****************************************************************************
6)
The positional index entry is like <d,frequency,<posting_list>>.
function nextTermInDoc(t,off,<n',f,<p1,p2....,pn>>)
{
// P[] = array of posting list fetched from <n',f,<p1,p2....,pn>>
// l[] = array of lengths of these posting lists
static c = []; //last index positions for terms
current = off
if(l[t] == 0 || P[l[t]] <= current) then
return infty;
if( P[1] > current) then
c[t] := 1;
return P[c[t]];
if( c[t] > 1 && P[c[t] - 1] <= current ) do
low := c[t] -1;
else
low := 1;
jump := 1;
high := low + jump;
while (high < l[t] && P[high] <= current) do
low := high;
jump := 2*jump;
high := low + jump;
if(high > l[t]) then
high := l[t];
c[t] = binarySearch(t, low, high, current)
return P[c[t]];
}
function nextDoc(t, current)
{
// P[] = array of document list fetched from <term: <<n',f,<p1,p2....,pn>, <n,f ,<p1,p2 ....,pn''>..........k entries of pos index>
// l[] = array of lengths of these posting lists
static c = []; //last index positions for terms
if(l[t] == 0 || P[l[t]] <= current) then
return infty;
if( P[1] > current) then
c[t] := 1;
return <P[c[t]],f,<p1,p2....>>;
if( c[t] > 1 && P[c[t] - 1] <= current ) do
low := c[t] -1;
else
low := 1;
jump := 1;
high := low + jump;
while (high < l[t] && P[high] <= current) do
low := high;
jump := 2*jump;
high := low + jump;
if(high > l[t]) then
high := l[t];
c[t] = binarySearch(t, low, high, current)
return P[c[t]];
}
function next(t,n:m)
{
<n',f,<p1,p2....>> = nextDoc(t,n-1)
if(n==n')
off = m
else
off = -infinity
m' = nextTermInDoc(t,off,<n',f,<p1,p2....>>)
return n':m'
}
(Edited: 2022-03-14) <pre>
-- Damanpreet Kaur and Divyashree Jayaram
10) Fenestrate
For char 5 grams the word would be split into following terms-
.fene , fenes , enest, nestr, estra, strat, trate, rate.
Stopping - In IR systems stopwords are stripped from the query before doing an index look-up. These stopwords often include function words. Function words are words that have no well-defined meanings in and of themselves; rather, they modify words or indicate grammatical relationships.
The process of stopping is also applied to the corpus before the creation of the index.
Stopping helps to reduce index size and also decreases the query processing time.
For instance- A and B
It would be converted to A B
Stemming- It is the process of an IR system where objective is to reduce each term to its root form. for example - "runs" to match "running"
Potter stemmer rules
sses => ss
ies => I
ss => ss (Stop execution)
s =>
*****************************************************************************
6)
The positional index entry is like <d,frequency,<posting_list>>.
function nextTermInDoc(t,off,<n',f,<p1,p2....,pn>>)
{
// P[] = array of posting list fetched from <n',f,<p1,p2....,pn>>
// l[] = array of lengths of these posting lists
static c = []; //last index positions for terms
current = off
if(l[t] == 0 || P[l[t]] <= current) then
return infty;
if( P[1] > current) then
c[t] := 1;
return P[c[t]];
if( c[t] > 1 && P[c[t] - 1] <= current ) do
low := c[t] -1;
else
low := 1;
jump := 1;
high := low + jump;
while (high < l[t] && P[high] <= current) do
low := high;
jump := 2*jump;
high := low + jump;
if(high > l[t]) then
high := l[t];
c[t] = binarySearch(t, low, high, current)
return P[c[t]];
}
function nextDoc(t, current)
{
// P[] = array of document list fetched from <term: <<n',f,<p1,p2....,pn>, <n'',f'',<p1'',p2''....,pn''>..........k entries of pos index>
// l[] = array of lengths of these posting lists
static c = []; //last index positions for terms
if(l[t] == 0 || P[l[t]] <= current) then
return infty;
if( P[1] > current) then
c[t] := 1;
return <P[c[t]],f,<p1,p2....>>;
if( c[t] > 1 && P[c[t] - 1] <= current ) do
low := c[t] -1;
else
low := 1;
jump := 1;
high := low + jump;
while (high < l[t] && P[high] <= current) do
low := high;
jump := 2*jump;
high := low + jump;
if(high > l[t]) then
high := l[t];
c[t] = binarySearch(t, low, high, current)
return P[c[t]];
}
function next(t,n:m)
{
<n',f,<p1,p2....>> = nextDoc(t,n-1)
if(n==n')
off = m
else
off = -infinity
m' = nextTermInDoc(t,off,<n',f,<p1,p2....>>)
return n':m'
}
</pre>
1.) Nishanth and Rebecca
a. Probability Ranking Principle: If an IR system's response to each query is a ranking of the documents in the collection in order of decreasing probability of relevance, then the overall effectiveness of the system to its users will be maximized.
b. Specificity: the document measures the degree to which its contents are focused on the information need. For example, the document might satisfy the need but also contain lots of other garbage. Example : The results might have not been specific.
c. Exhaustivity: document reflects the degree to which it covers the information related to the topic.
d. Novelty: from a document list reflects how much new information the n-th search result gives to the user given the previous results.
8.)

1.) Nishanth and Rebecca
a. <u>Probability Ranking Principle</u>: If an IR system's response to each query is a ranking of the documents in the collection in order of decreasing probability of relevance, then the overall effectiveness of the system to its users will be maximized.
b. <u>Specificity</u>: the document measures the degree to which its contents are focused on the information need. For example, the document might satisfy the need but also contain lots of other garbage. Example : The results might have not been specific.
c. <u>Exhaustivity</u>: document reflects the degree to which it covers the information related to the topic.
d. <u>Novelty</u>: from a document list reflects how much new information the n-th search result gives to the user given the previous results.
8.)
((resource:IMG-6728.jpg|Resource Description for IMG-6728.jpg))
Venkat and Archit
2) Consider the sentence "two bees or not two fleas". What is M1(bees|two)? Describe how a first order model can be smoothed by a zero'th order model.

9) Briefly explain how autoloading works in PHP. What is Composer? Give an example of a couple of its commands.

Venkat and Archit
2) Consider the sentence "two bees or not two fleas". What is M1(bees|two)? Describe how a first order model can be smoothed by a zero'th order model.
((resource:2.jpg|Resource Description for 2.jpg))
9) Briefly explain how autoloading works in PHP. What is Composer? Give an example of a couple of its commands.
((resource:9.jpg|Resource Description for 9.jpg))
By Lakshmi Prasanna Gorrepati and Gargi Sheguri
Question 5

Question 8

(Edited: 2022-03-14)
By Lakshmi Prasanna Gorrepati and Gargi Sheguri
Question 5
((resource:midterm-Q5.jpeg|Resource Description for midterm-Q5.jpeg))
Question 8
((resource:midterm-Q8.jpeg|Resource Description for midterm-Q8.jpeg))
Aarsh, Kaushik, Inderpreet
Answer 4:
nextPhrase(t[1],t[2], .., t[n], position)
{
v:=position
for i = 1 to n do
v:= next(t[i], v)
if v == infinity
return [infinity, infinity]
u := v
for i := n-1 downto 1 do
u := prev(t[i],u)
if(v-u == n - 1) then
return [u, v]
else
return nextPhrase(t[1],t[2], .., t[n], u)
}
l = minimum length of ti's posting list.
L = maximum length of ti's posting list.
n = number of terms in phrase
Runtime
Sequential: O(n.L)
Binary: O(n.l.log(L))
Exponential: O(n.l.(log(L/l)+1))
Answer 10:
If n =5, the the character n-grams for the word fenestrate :
_fenestrate_
_fene, fenes, enest, nestr, estra, strat, trate, rate_
stopping :
Stopping reflects the observation that many words, such as → the, I have little value so stopping removes these words to make the retrieval more precise and reduces the size of the index
Stemming:
Stemming considers the morphology of the terms, reducing each term to its root form for comparisons.
Rules for porter stemmer:
sses → ss
ies → i
ss → ss
s →
(Edited: 2022-03-15) Aarsh, Kaushik, Inderpreet
Answer 4:
nextPhrase(t[1],t[2], .., t[n], position)
{
v:=position
for i = 1 to n do
v:= next(t[i], v)
if v == infinity
return [infinity, infinity]
u := v
for i := n-1 downto 1 do
u := prev(t[i],u)
if(v-u == n - 1) then
return [u, v]
else
return nextPhrase(t[1],t[2], .., t[n], u)
}
l = minimum length of ti's posting list.
L = maximum length of ti's posting list.
n = number of terms in phrase
Runtime
Sequential: O(n.L)
Binary: O(n.l.log(L))
Exponential: O(n.l.(log(L/l)+1))
Answer 10:
If n =5, the the character n-grams for the word fenestrate :
_fenestrate_
_fene, fenes, enest, nestr, estra, strat, trate, rate_
stopping :
Stopping reflects the observation that many words, such as → the, I have little value so stopping removes these words to make the retrieval more precise and reduces the size of the index
Stemming:
Stemming considers the morphology of the terms, reducing each term to its root form for comparisons.
Rules for porter stemmer:
sses → ss
ies → i
ss → ss
s →
Teammate : Atharva Sharma
Question 3:
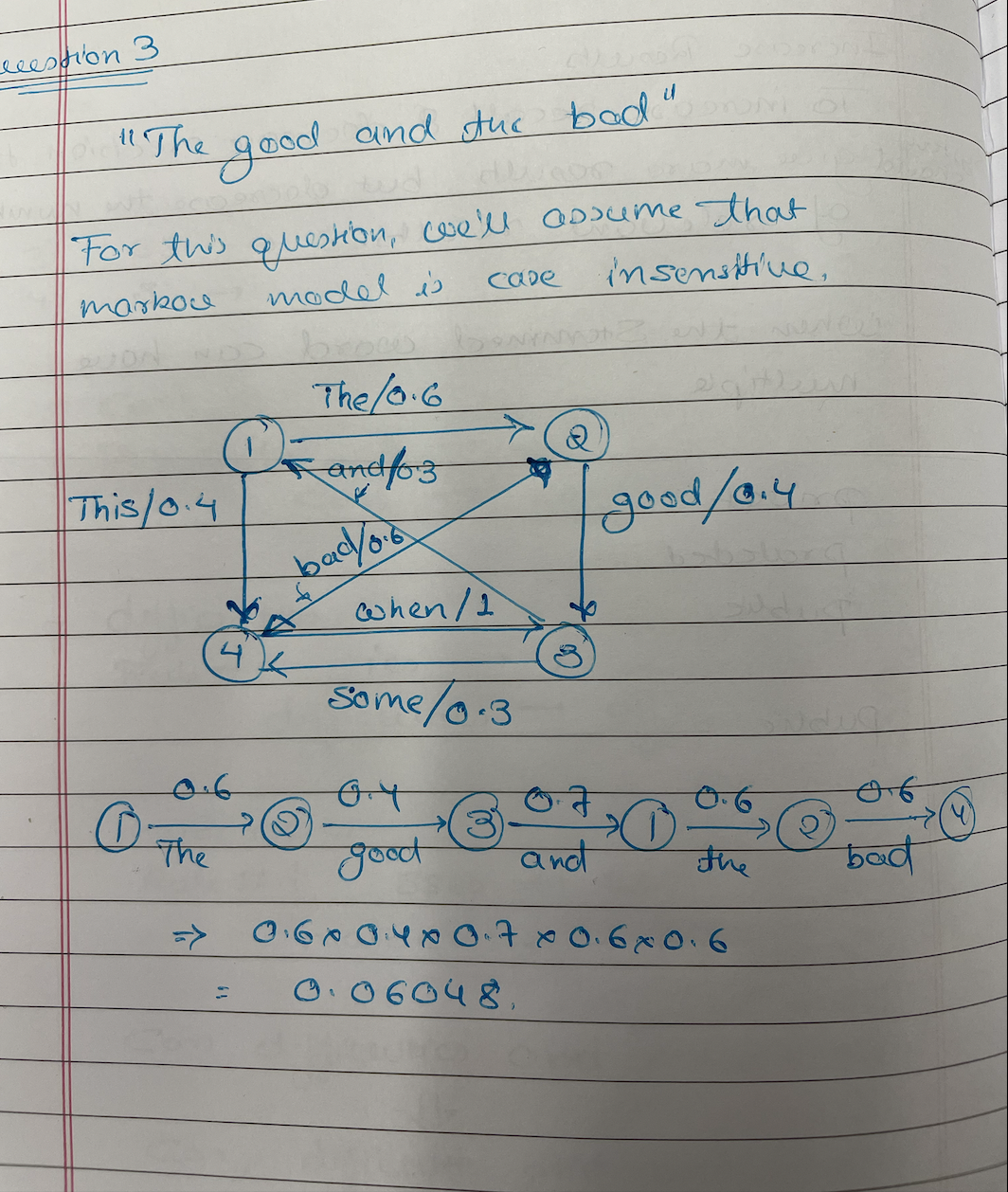
Question 10:
Character n-grams
fenestrate
n = 5
Answer: _fene, fenes, enest, nestr, estra, strat, trate, rate_
What is stopping?
Eliminating stopwords that have no well-defined meanings of themselves like the prepositions from the corpus before we create an inverted index for it is called stopping
What is stemming?
Stemming is a technique used to extract the base form and reduce it to root form of the word.
Example: caller, calling, calls will be stemmed to call.
Give an example of the kinds of rules used by a Porter stemmer.
Rules:
(Edited: 2022-03-14) sses -> ss ies - > i ss -> ss s ->
'''Teammate''': Atharva Sharma
'''Question 3:'''
((resource:Screen Shot 2022-03-14 at 2.31.55 PM.png|Resource Description for Screen Shot 2022-03-14 at 2.31.55 PM.png))
'''Question 10:'''
Character n-grams
fenestrate
n = 5
Answer: _fene, fenes, enest, nestr, estra, strat, trate, rate_
What is stopping?
Eliminating stopwords that have no well-defined meanings of themselves like the prepositions from the corpus before we create an inverted index for it is called stopping
What is stemming?
Stemming is a technique used to extract the base form and reduce it to root form of the word.
Example: caller, calling, calls will be stemmed to call.
Give an example of the kinds of rules used by a Porter stemmer.
Rules:
sses -> ss
ies - > i
ss -> ss
s ->
Cheng-En & Neenu
(Edited: 2022-03-14) Cheng-En & Neenu
Problem 7.
((resource:Screen Shot 2022-03-14 at 3.16.55 PM.png|Resource Description for Screen Shot 2022-03-14 at 3.16.55 PM.png))
((resource:Screen Shot 2022-03-14 at 3.17.38 PM.png|Resource Description for Screen Shot 2022-03-14 at 3.17.38 PM.png))
Problem 8.
((resource:Screen Shot 2022-03-14 at 3.15.43 PM.png|Resource Description for Screen Shot 2022-03-14 at 3.15.43 PM.png))
((resource:Screen Shot 2022-03-14 at 3.15.53 PM.png|Resource Description for Screen Shot 2022-03-14 at 3.15.53 PM.png))
((resource:Screen Shot 2022-03-14 at 3.21.17 PM.png|Resource Description for Screen Shot 2022-03-14 at 3.21.17 PM.png))
2022-03-15
Gokul and Nimesh

10) Char 5 grams for Fenestrate
.fene, fenes, enest, nestr, estra, strat, trate, rate.
(Edited: 2022-03-15) Stopping - The process of removing stopwords that do not really contribute to the meaning. These words can be prepositions, articles etc. Stripping of these words from the query before doing an index look up is called stopping.For instance- A and B It would be converted to A B
Stemming- The process of reducing a word to its root word known as lemma(lexeme). The function that does this is called a stemmer.Potter stemmer rules sses => ss ies => I ss => ss (Stop execution) s =>
Gokul and Nimesh
((resource:1.jpeg|Resource Description for 1.jpeg))
10) Char 5 grams for Fenestrate
.fene, fenes, enest, nestr, estra, strat, trate, rate.
Stopping - The process of removing stopwords that do not really contribute to the meaning. These words can be prepositions, articles etc. Stripping of these words from the query before doing an index look up is called stopping.
For instance- A and B
It would be converted to A B
Stemming- The process of reducing a word to its root word known as lemma(lexeme). The function that does this is called a stemmer.
Potter stemmer rules
sses => ss
ies => I
ss => ss (Stop execution)
s =>
(c) 2026 Yioop - PHP Search Engine